申明
基于Java 17

atomic
package java.util.concurrent.atomic
一个小型类工具包,支持对单个变量进行无锁线程安全编程。原子类的实例维护使用方法访问和更新的值,否则可用于使用关联原子 VarHandle 操作的字段。类 AtomicBoolean、AtomicInteger、AtomicLong 和 AtomicReference 的实例都提供对相应类型的单个变量的访问和更新。每个类还为该类型提供适当的实用工具方法。例如,类 AtomicLong 和 AtomicInteger 提供原子增量方法。一种应用是生成序列号,如:
class Sequencer {
private final AtomicLong sequenceNumber
= new AtomicLong(17);
public long next() {
return sequenceNumber.getAndIncrement();
}
}
所包含值的任意转换由低级读取-修改-写入操作(如 compareAndSet)和更高级别的方法(如 getAndUpdate)提供。这些类不是 java.lang.Integer 和相关类的通用替代品。它们没有定义诸如equals,hashCode和compareTo之类的方法。由于原子变量预计会发生突变,因此它们是哈希表键的糟糕选择。AtomicIntegerArray、AtomicLongArray 和 AtomicReferenceArray 类进一步扩展了对这些类型的数组的原子操作支持。这些类在为其数组元素提供易失性访问语义方面也值得注意。除了表示单个值和数组的类之外,此包还包含 Updater 类,这些类可用于获取对任何选定类的任何选定易失性字段的 compareAndSet 和相关操作。这些类早于 VarHandle 的引入,用途更有限。AtomicReferenceFieldUpdater、AtomicIntegerFieldUpdater 和 AtomicLongFieldUpdater 是基于反射的实用程序,提供对关联字段类型的访问。这些主要用于原子数据结构,其中同一节点的几个易失性字段(例如,树节点的链接)独立地受到原子更新的影响。这些类在如何以及何时使用原子更新方面提供了更大的灵活性,但代价是基于反射的设置更笨拙、使用不太方便和保证更弱。类将单个布尔值与引用相关联。例如,此位可以在数据结构中使用,以表示所引用的对象已在逻辑上被删除。类将整数值与引用相关联。例如,这可用于表示对应于一系列更新的版本号。
AtomicBoolean
概要
可以原子方式更新的布尔值。有关原子访问属性的说明,请参阅 VarHandle 规范。原子布尔值用于原子更新flag等应用程序,不能用作Boolean的替代品。
内部维护了一个voilate 的 int 变量,该值代表当前值
private volatile int value;
其余方法依赖 VarHandle类的方法实现原子的更新值。
Volatile boolean 和 AtomicBoolean的不同之处
使用 AtomicBoolean 所有读取和写入操作都是原子的。对于volatile 布尔值,当两个线程同时访问变量时,您仍然需要处理竞争条件。即AtomicBoolean可以保证原子性,volatile能确保内存可见性
private volatile boolean isStart;
private AtomicBoolean atomicBooleanStart =new AtomicBoolean(false);
public void start() {
if(!isStart) {
isStart = true;
//do something
}
}
public void stop() {
if (atomicBooleanStart.compareAndSet(false, true)) {
//doSomething
}
}
AtomicInteger
AtomicInteger 和AtomicBoolean 类似
什么时候使用AtomicInteger
一般我们可以把它作为一个原子计数器来使用,例,生成伪随机数
public class AtomicPseudoRandom extends PseudoRandom {
private final AtomicInteger seed;
AtomicPseudoRandom(int seed) {
this.seed = new AtomicInteger(seed);
}
public int nextInt(int n) {
while (true) {
int s = seed.get();
int nextSeed = calculateNext(s);
if (seed.compareAndSet(s, nextSeed)) {
int remainder = s % n;
return remainder > 0 ? remainder : remainder + n;
}
}
}
}
public class PseudoRandom {
int calculateNext(int prev) {
prev ^= prev << 6;
prev ^= prev >>> 21;
prev ^= (prev << 7);
return prev;
}
}
AtomicIntegerArray
概述
类 AtomicIntegerArray 表示一个 int(整数)类型的数组可以以原子方式更新。通过传入普通的int数组来构造为AtomicIntegerArray
例子
private static AtomicIntegerArray atomicIntegerArray = new AtomicIntegerArray(10);
public static void main(final String[] arguments) throws InterruptedException {
for (int i = 0; i<atomicIntegerArray.length(); i++) {
atomicIntegerArray.set(i, 1);
}
Thread t1 = new Thread(new Increment());
Thread t2 = new Thread(new Compare());
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("Values: ");
for (int i = 0; i<atomicIntegerArray.length(); i++) {
System.out.print(atomicIntegerArray.get(i) + " ");
}
}
static class Increment implements Runnable {
public void run() {
for(int i = 0; i<atomicIntegerArray.length(); i++) {
int add = atomicIntegerArray.incrementAndGet(i);
System.out.println("T1 Thread " + Thread.currentThread().getId()
+ ", index " +i + ", value: "+ add);
}
}
}
static class Compare implements Runnable {
public void run() {
for(int i = 0; i<atomicIntegerArray.length(); i++) {
boolean swapped = atomicIntegerArray.compareAndSet(i, 2, 3);
if(swapped) {
System.out.println("T2 Thread " + Thread.currentThread().getId()
+ ", index " +i + ", value: 3");
}
}
}
}
由于atomicIntegerArray.compareAndSet cas操作可能会失败,所以最终结果不一定都是3.
AtomicIntegerFieldUpdater
概述
从名字看,AtomicIntegerFieldUpdater 表示能原子的更新一个类的整形变量。
基于反射的实用程序,可以对指定类的指定volatile int字段进行原子更新。 此类设计用于原子数据结构,其中同一节点的多个字段独立地受原子更新的影响。
请注意, compareAndSet方法的保证比其他原子类弱。 因为此类无法确保该字段的所有使用都适用于原子访问的目的,所以它只能保证在同一更新程序上对compareAndSet和set其他调用的原子性。
T类型的参数的对象参数不是传递给newUpdater(java.lang.Class<U>, java.lang.String)的类的实例,将导致抛出ClassCastException 。
AtomicLong
概述
AtomicLong与 AtomicInteger原理一样,看AtomicInteger ,只是内部维护的value 是long类型的。此外内部的 VALUE依然通过Unsafe类实现,并没有使用VarHandle 实现,因为存在未解析的循环启动依赖项。
AtomicLongArray
概述
AtomicLongArray 与AtomicIntegerArray 一样 看 AtomicIntegerArray, 内部维护 private final long[] array;
AtomicLongFieldUpdater
概述
AtomicLongFieldUpdater与AtomicIntegerFieldUpdater类似,看 AtomicIntegerFieldUpdater
AtomicMarkableReference
概述
AtomicMarkableReference 维护一个对象引用和一个标记位,该标记位可以原子方式更新。它封装了对对象的引用和布尔标志。这两个字段耦合在一起,可以一起或单独原子地更新。AtomicMarkableReference也可以是针对ABA问题的可能补救措施 。 布尔标志含义是对象是否被更改过,而不关心被更改的次数,无论一次或多次。
public class AtomicMarkableReferenceUnitTest {
class Employee {
private int id;
private String name;
Employee(int id, String name) {
this.id = id;
this.name = name;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
@Test
void givenMarkValueAsTrue_whenUsingIsMarkedMethod_thenMarkValueShouldBeTrue() {
Employee employee = new Employee(123, "Mike");
AtomicMarkableReference<Employee> employeeNode = new AtomicMarkableReference<Employee>(employee, true);
Assertions.assertTrue(employeeNode.isMarked());
}
@Test
void givenMarkValueAsFalse_whenUsingIsMarkedMethod_thenMarkValueShouldBeFalse() {
Employee employee = new Employee(123, "Mike");
AtomicMarkableReference<Employee> employeeNode = new AtomicMarkableReference<Employee>(employee, false);
Assertions.assertFalse(employeeNode.isMarked());
}
@Test
void whenUsingGetReferenceMethod_thenCurrentReferenceShouldBeReturned() {
Employee employee = new Employee(123, "Mike");
AtomicMarkableReference<Employee> employeeNode = new AtomicMarkableReference<Employee>(employee, true);
Assertions.assertEquals(employee, employeeNode.getReference());
}
@Test
void whenUsingGetMethod_thenCurrentReferenceAndMarkShouldBeReturned() {
Employee employee = new Employee(123, "Mike");
AtomicMarkableReference<Employee> employeeNode = new AtomicMarkableReference<Employee>(employee, true);
boolean[] markHolder = new boolean[1];
Employee currentEmployee = employeeNode.get(markHolder);
Assertions.assertEquals(employee, currentEmployee);
Assertions.assertTrue(markHolder[0]);
}
@Test
void givenNewReferenceAndMark_whenUsingSetMethod_thenCurrentReferenceAndMarkShouldBeUpdated() {
Employee employee = new Employee(123, "Mike");
AtomicMarkableReference<Employee> employeeNode = new AtomicMarkableReference<Employee>(employee, true);
Employee newEmployee = new Employee(124, "John");
employeeNode.set(newEmployee, false);
Assertions.assertEquals(newEmployee, employeeNode.getReference());
Assertions.assertFalse(employeeNode.isMarked());
}
@Test
void givenTheSameObjectReference_whenUsingAttemptMarkMethod_thenMarkShouldBeUpdated() {
Employee employee = new Employee(123, "Mike");
AtomicMarkableReference<Employee> employeeNode = new AtomicMarkableReference<Employee>(employee, true);
Assertions.assertTrue(employeeNode.attemptMark(employee, false));
Assertions.assertFalse(employeeNode.isMarked());
}
@Test
void givenDifferentObjectReference_whenUsingAttemptMarkMethod_thenMarkShouldNotBeUpdated() {
Employee employee = new Employee(123, "Mike");
AtomicMarkableReference<Employee> employeeNode = new AtomicMarkableReference<Employee>(employee, true);
Employee expectedEmployee = new Employee(123, "Mike");
Assertions.assertFalse(employeeNode.attemptMark(expectedEmployee, false));
Assertions.assertTrue(employeeNode.isMarked());
}
@Test
void givenCurrentReferenceAndCurrentMark_whenUsingCompareAndSet_thenReferenceAndMarkShouldBeUpdated() {
Employee employee = new Employee(123, "Mike");
AtomicMarkableReference<Employee> employeeNode = new AtomicMarkableReference<Employee>(employee, true);
Employee newEmployee = new Employee(124, "John");
Assertions.assertTrue(employeeNode.compareAndSet(employee, newEmployee, true, false));
Assertions.assertEquals(newEmployee, employeeNode.getReference());
Assertions.assertFalse(employeeNode.isMarked());
}
@Test
void givenNotCurrentReferenceAndCurrentMark_whenUsingCompareAndSet_thenReferenceAndMarkShouldNotBeUpdated() {
Employee employee = new Employee(123, "Mike");
AtomicMarkableReference<Employee> employeeNode = new AtomicMarkableReference<Employee>(employee, true);
Employee newEmployee = new Employee(124, "John");
Assertions.assertFalse(employeeNode.compareAndSet(new Employee(1234, "Steve"), newEmployee, true, false));
Assertions.assertEquals(employee, employeeNode.getReference());
Assertions.assertTrue(employeeNode.isMarked());
}
@Test
void givenCurrentReferenceAndNotCurrentMark_whenUsingCompareAndSet_thenReferenceAndMarkShouldNotBeUpdated() {
Employee employee = new Employee(123, "Mike");
AtomicMarkableReference<Employee> employeeNode = new AtomicMarkableReference<Employee>(employee, true);
Employee newEmployee = new Employee(124, "John");
Assertions.assertFalse(employeeNode.compareAndSet(employee, newEmployee, false, true));
Assertions.assertEquals(employee, employeeNode.getReference());
Assertions.assertTrue(employeeNode.isMarked());
}
@Test
void givenNotCurrentReferenceAndNotCurrentMark_whenUsingCompareAndSet_thenReferenceAndMarkShouldNotBeUpdated() {
Employee employee = new Employee(123, "Mike");
AtomicMarkableReference<Employee> employeeNode = new AtomicMarkableReference<Employee>(employee, true);
Employee newEmployee = new Employee(124, "John");
Assertions.assertFalse(employeeNode.compareAndSet(new Employee(1234, "Steve"), newEmployee, false, true));
Assertions.assertEquals(employee, employeeNode.getReference());
Assertions.assertTrue(employeeNode.isMarked());
}
@Test
void givenCurrentReferenceAndCurrentMark_whenUsingWeakCompareAndSet_thenReferenceAndMarkShouldBeUpdated() {
Employee employee = new Employee(123, "Mike");
AtomicMarkableReference<Employee> employeeNode = new AtomicMarkableReference<Employee>(employee, true);
Employee newEmployee = new Employee(124, "John");
Assertions.assertTrue(employeeNode.weakCompareAndSet(employee, newEmployee, true, false));
Assertions.assertEquals(newEmployee, employeeNode.getReference());
Assertions.assertFalse(employeeNode.isMarked());
}
@Test
void givenNotCurrentReferenceAndCurrentMark_whenUsingWeakCompareAndSet_thenReferenceAndMarkShouldNotBeUpdated() {
Employee employee = new Employee(123, "Mike");
AtomicMarkableReference<Employee> employeeNode = new AtomicMarkableReference<Employee>(employee, true);
Employee newEmployee = new Employee(124, "John");
Assertions.assertFalse(employeeNode.weakCompareAndSet(new Employee(1234, "Steve"), newEmployee, true, false));
Assertions.assertEquals(employee, employeeNode.getReference());
Assertions.assertTrue(employeeNode.isMarked());
}
@Test
void givenCurrentReferenceAndNotCurrentMark_whenUsingWeakCompareAndSet_thenReferenceAndMarkShouldNotBeUpdated() {
Employee employee = new Employee(123, "Mike");
AtomicMarkableReference<Employee> employeeNode = new AtomicMarkableReference<Employee>(employee, true);
Employee newEmployee = new Employee(124, "John");
Assertions.assertFalse(employeeNode.weakCompareAndSet(employee, newEmployee, false, true));
Assertions.assertEquals(employee, employeeNode.getReference());
Assertions.assertTrue(employeeNode.isMarked());
}
@Test
void givenNotCurrentReferenceAndNotCurrentMark_whenUsingWeakCompareAndSet_thenReferenceAndMarkShouldNotBeUpdated() {
Employee employee = new Employee(123, "Mike");
AtomicMarkableReference<Employee> employeeNode = new AtomicMarkableReference<Employee>(employee, true);
Employee newEmployee = new Employee(124, "John");
Assertions.assertFalse(employeeNode.weakCompareAndSet(new Employee(1234, "Steve"), newEmployee, false, true));
Assertions.assertEquals(employee, employeeNode.getReference());
Assertions.assertTrue(employeeNode.isMarked());
}
}
AtomicReference
概述
AtomicReference 与AtomicInteger类似,只是一个针对object,一个针对interger
AtomicReferenceArray
概述
AtomicReferenceArray与AtomicIntegerArray类似,看AtomicIntegerArray ,AtomicReferenceArray操作对象是一个对象数组
AtomicReferenceFieldUpdater
概述
AtomicReferenceFieldUpdater与AtomicIntegerFieldUpdater类似,看AtomicIntegerFieldUpdater,操作对象为一个类的volatile修饰的对象属性
TransferQueue
概述
TransferQueue 是一种可以让生产者等待消费者接收元素的 BlockingQueue。在消息传递应用中,TransferQueue 可能很有用,在这种应用中,生产者有时(使用方法 transfer)会等待消费者调用 take 或 poll 接收元素,而在其他时候则会(通过方法 put)将元素入队而不等待接收。也有非阻塞和超时版本的 tryTransfer。也可以通过 hasWaitingConsumer 查询 TransferQueue,看看是否有任何线程在等待项目,这与 peek 操作是反向类比。像其他阻塞队列一样,TransferQueue 也可能具有容量限制。如果是这样,则尝试的转移操作可能会先阻塞等待可用空间,然后再阻塞等待消费者接收。注意,在容量为零的队列(例如 SynchronousQueue)中,put 和 transfer 实际上是等价的。
方法解析
tryTransfer 将元素立即传输给正在等待的消费者(如果可能的话)。更精确地说,如果已经有一个消费者正在等待接收它(在 take 或定时 poll 中),则立即传输指定的元素,否则返回 false,而不排队元素。
transfer 将元素传递给消费者,如果必要,则等待。更精确地说,如果已经有一个消费者在等待接收它(在 take 或者定时 poll 中),则立即传递指定的元素,否则等待直到元素被消费者接收。
hasWaitingConsumer 如果至少有一个消费者正在等待通过 take 或定时 poll 接收一个元素,则返回 true。返回值表示当前的情况。
getWaitingConsumerCount 此方法返回通过take或timed poll接收元素的消费者数量的估计值。返回值表示当前事态的近似状态,如果消费者已完成或放弃等待,则可能不准确。此值可能对监控和启发式方法有用,但不适用于同步控制。此方法的实现可能比hasWaitingConsumer明显慢。
RecursiveAction
概述
一个递归的无结果的ForkJoinTask。此类建立了将无结果操作参数化为Void ForkJoinTasks的约定。因为null是Void类型的唯一有效值,因此完成后诸如join等方法总是返回null。 样例用法。这是一个简单但完整的ForkJoin排序,可对给定的long []数组进行排序:
static class SortTask extends RecursiveAction {
final long[] array; final int lo, hi;
SortTask(long[] array, int lo, int hi) {
this.array = array; this.lo = lo; this.hi = hi;
}
SortTask(long[] array) { this(array, 0, array.length); }
protected void compute() {
if (hi - lo < THRESHOLD)
sortSequentially(lo, hi);
else {
int mid = (lo + hi) >>> 1;
invokeAll(new SortTask(array, lo, mid),
new SortTask(array, mid, hi));
merge(lo, mid, hi);
}
}
// implementation details follow:
static final int THRESHOLD = 1000;
void sortSequentially(int lo, int hi) {
Arrays.sort(array, lo, hi);
}
void merge(int lo, int mid, int hi) {
long[] buf = Arrays.copyOfRange(array, lo, mid);
for (int i = 0, j = lo, k = mid; i < buf.length; j++)
array[j] = (k == hi || buf[i] < array[k]) ?
buf[i++] : array[k++];
}
}
您可以通过创建new SortTask(anArray)并在ForkJoinPool中调用它来对anArray进行排序。作为一个更具体的简单示例,以下任务增加数组的每个元素:
class IncrementTask extends RecursiveAction {
final long[] array; final int lo, hi;
IncrementTask(long[] array, int lo, int hi) {
this.array = array; this.lo = lo; this.hi = hi;
}
protected void compute() {
if (hi - lo < THRESHOLD) {
for (int i = lo; i < hi; ++i)
array[i]++;
}
else {
int mid = (lo + hi) >>> 1;
invokeAll(new IncrementTask(array, lo, mid),
new IncrementTask(array, mid, hi));
}
}
}
以下示例说明了一些可能导致更好性能的改进和惯用法:RecursiveActions不需要完全递归,只要它们保持基本的分治方法即可。这是一个类,通过仅对重复除以二的右侧进行分裂,并通过next引用链跟踪它们,对double数组的每个元素的平方和。它使用基于方法getSurplusQueuedTaskCount的动态阈值,但通过直接对未被盗用的任务执行叶动作而不是进一步细分来平衡潜在的过度分割。
double sumOfSquares(ForkJoinPool pool, double[] array) {
int n = array.length;
Applyer a = new Applyer(array, 0, n, null);
pool.invoke(a);
return a.result;
}
class Applyer extends RecursiveAction {
final double[] array;
final int lo, hi;
double result;
Applyer next; // keeps track of right-hand-side tasks
Applyer(double[] array, int lo, int hi, Applyer next) {
this.array = array; this.lo = lo; this.hi = hi;
this.next = next;
}
double atLeaf(int l, int h) {
double sum = 0;
for (int i = l; i < h; ++i) // perform leftmost base step
sum += array[i] * array[i];
return sum;
}
protected void compute() {
int l = lo;
int h = hi;
Applyer right = null;
while (h - l > 1 && getSurplusQueuedTaskCount() <= 3) {
int mid = (l + h) >>> 1;
right = new Applyer(array, mid, h, right);
right.fork();
h = mid;
}
double sum = atLeaf(l, h);
while (right != null) {
if (right.tryUnfork()) // directly calculate if not stolen
sum += right.atLeaf(right.lo, right.hi);
else {
right.join();
sum += right.result;
}
right = right.next;
}
result = sum;
}
}
ExecutorCompletionService
概述
ExecutorCompletionService是一个使用提供的Executor执行任务的CompletionService。该类安排提交的任务在完成后放置在可使用take访问的队列上。该类足够轻量,适用于处理任务组时的瞬态使用。 使用示例。假设你有一组解决某个问题的解算器,每个都返回某类型Result的值,并希望它们并发运行,在某种方法use(Result r)中处理每个返回非空值的结果。你可以这样写:
void solve(Executor e,
Collection<Callable<Result>> solvers)
throws InterruptedException, ExecutionException {
CompletionService<Result> cs
= new ExecutorCompletionService<>(e);
solvers.forEach(cs::submit);
for (int i = solvers.size(); i > 0; i--) {
Result r = cs.take().get();
if (r != null)
use(r);
}
}
假设你希望使用任务集合中的第一个非空结果,忽略遇到异常的任何任务,并在第一个任务准备就绪时取消所有其他任务:
void solve(Executor e,
Collection<Callable<Result>> solvers)
throws InterruptedException {
CompletionService<Result> cs
= new ExecutorCompletionService<>(e);
int n = solvers.size();
List<Future<Result>> futures = new ArrayList<>(n);
Result result = null;
try {
solvers.forEach(solver -> futures.add(cs.submit(solver)));
for (int i = n; i > 0; i--) {
try {
Result r = cs.take().get();
if (r != null) {
result = r;
break;
}
} catch (ExecutionException ignore) {}
}
} finally {
futures.forEach(future -> future.cancel(true));
}
if (result != null)
use(result);
}
Delayed
概述
一种混合式界面,用于标记在给定延迟后应该采取行动的对象。 此接口的实现必须定义一个compareTo方法,该方法提供与其getDelay方法一致的排序。
/*返回与此对象关联的剩余延迟,以给定时间单位表示。
参数:unit - 时间单位
返回值:剩余延迟;零或负值表示延迟已经过去。*/
long getDelay(TimeUnit unit);
BlockingQueue
概述
除了支持在检索元素时等待队列变为非空和在存储元素时等待空间可用的操作的 Queue 之外,还支持阻塞队列方法。在四种形式中,使用不同的方法处理无法立即满足的操作,但在将来的某个时刻可能会满足:一种抛出异常,第二种返回特殊值(null 或 false,取决于操作),第三种在操作能够成功之前无限期地阻塞当前线程,第四种在放弃之前仅阻塞给定的最大时间限制。这些方法在以下表中总结:
BlockingQueue 实现不接受空元素。尝试添加、放置或提供 null 时,实现会抛出 NullPointerException。null 用作标志值来指示 poll 操作的失败。 BlockingQueue 可能具有容量限制。在任何给定时间内,它都可能有超出哪些没有额外元素可以在不阻塞的情况下放入的 remainingCapacity。没有任何内在容量约束的 BlockingQueue 总是报告 remaining capacity 为 Integer.MAX_VALUE。
BlockingQueue 实现是设计用于生产者 - 消费者队列的,但它们还支持 Collection 接口。因此,例如,可以使用 remove(x) 从队列中删除任意元素。但是,这样的操作通常并不能很高效地执行,并且仅计划在偶尔使用时使用,例如在取消排队的消息时。BlockingQueue 实现是线程安全的。所有排队方法都使用内部锁或其他形式的并发控制以原子方式实现其效果。但是,除非在实现中另有说明,否则批量 Collection 操作 addAll、containsAll、retainAll 和 removeAll 不一定是原子执行的。因此,例如,addAll(c) 在添加 c 中的一些元素之后可能失败(抛出异常)。
BlockingQueue 是一种队列,同时支持在取出元素时等待队列变为非空,以及在存储元素时等待空间可用的操作。BlockingQueue 方法有四种形式,用于处理无法立即满足但可能在将来某个时刻满足的操作:一种会抛出异常,第二种会返回一个特殊值(要么是 null,要么是 false,取决于操作),第三种会使当前线程无限期地阻塞,直到操作能够成功,第四种在放弃之前会在给定的最大时间限制内阻塞当前线程。
内存一致性效应:与其他并发集合一样,在将对象放入 BlockingQueue 之前的线程操作先于在另一个线程中从 BlockingQueue 访问或删除该元素之后的操作发生。
方法解析
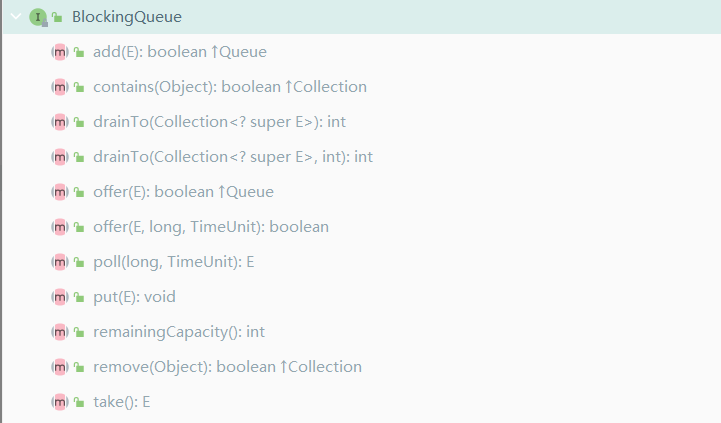
add 增加一个元索 如果队列已满,则抛出一个IIIegaISlabEepeplian异常
remove 移除并返回队列头部的元素 如果队列为空,则抛出一个NoSuchElementException异常 element 返回队列头部的元素 如果队列为空,则抛出一个NoSuchElementException异常
offer 添加一个元素并返回true 如果队列已满,则返回false
poll 移除并返问队列头部的元素 如果队列为空,则返回null
peek 返回队列头部的元素 如果队列为空,则返回null
put 添加一个元素 如果队列满,则阻塞
take 移除并返回队列头部的元素 如果队列为空,则阻塞
drainTo 把此队列中的所有可用元素删除并添加到给定集合中。此操作可能比多次轮询此队列更有效。尝试将元素添加到集合c中时遇到故障可能会导致在抛出相关异常时在这两个集合中的元素均不存在,仅存在一个或两个。尝试将队列排空到自身会导致 IllegalArgumentException。此外,如果在此操作进行时指定的集合被修改,则此操作的行为是未定义的。
CountDownLatch
概述
CountDownLatch 是一种同步辅助工具,允许一个或多个线程等待直到在其他线程中执行的一组操作完成。 CountDownLatch 使用给定的计数进行初始化。当前计数达到零(由于 countDown 方法的调用)时,await 方法将阻塞,之后所有等待的线程都将被释放,并且任何后续的 await 调用都将立即返回。这是一个一次性现象 - 计数无法重置。如果您需要重置计数的版本,请考虑使用 CyclicBarrier。 CountDownLatch 是一种多功能的同步工具,可用于多种目的。使用计数为 1 的 CountDownLatch 可以作为简单的开/关阀门:所有调用 await 的线程都将在闸门处等待,直到调用 countDown 的线程打开闸门。使用计数为 N 的 CountDownLatch 可以使一个线程等待,直到 N 个线程完成某些操作,或者某些操作已经完成 N 次。 CountDownLatch 的一个有用属性是,它不要求调用 countDown 的线程在继续之前等待计数到达零,它只是防止任何线程在 await 之后继续进行,直到所有线程都可以通过。
实现原理
内部的同步是由 继承 AbstractQueuedSynchronizer的实现的,CountDownLatch构造参数即是同步变量state的值,await 方法调用AQS的acquireSharedInterruptibly,countDown()即是释放共享锁 tryReleaseShared
protected int tryAcquireShared(int acquires) {
return (getState() == 0) ? 1 : -1;
}
该方法判断同步状态是不是同于0,再aqs中即当等于0时才能获取到锁
用例
public class AtomicIntegerTest {
private AtomicInteger mum = new AtomicInteger(0);
private int threadCounts=10;
public void increase(int j) {
mum.incrementAndGet();
try {
Thread.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+"循环次数"+j);
}
public int addNumber() {
CountDownLatch countDownLatch = new CountDownLatch(threadCounts);
for (int i = 0; i < threadCounts; i++) {
new Thread(()->{
for (int j = 0; j < 10; j++) {
increase(j);
}
countDownLatch.countDown();
},"thread-"+i).start();
}
try {
countDownLatch.await();//等待所有的线程执行完
} catch (InterruptedException e) {
e.printStackTrace();
}
return mum.get();
}
public static void main(String[] args) {
AtomicIntegerTest aiTest = new AtomicIntegerTest();
System.out.println(aiTest.addNumber());
}
}
//主线程要等所有子线程累加数字之后 才会打印最终的和。
Semaphore
概述
一个计数信号量。在概念上,信号量维护一组许可。每个 acquire 必要时阻塞,直到有许可证可用,然后获取它。每个 release 增加一个许可,可能释放阻塞的 acquirer。但是,实际上不使用许可对象;Semaphore 只保留可用数量的计数,并根据此进行操作。 信号量通常用于限制可以访问某些(物理或逻辑)资源的线程数。例如,这是一个使用信号量控制对项目池访问的类:
class Pool {
private static final int MAX_AVAILABLE = 100;
private final Semaphore available = new Semaphore(MAX_AVAILABLE, true);
public Object getItem() throws InterruptedException {
available.acquire();
return getNextAvailableItem();
}
public void putItem(Object x) {
if (markAsUnused(x))
available.release();
}
// Not a particularly efficient data structure; just for demo
protected Object[] items = ...; // whatever kinds of items being managed
protected boolean[] used = new boolean[MAX_AVAILABLE];
protected synchronized Object getNextAvailableItem() {
for (int i = 0; i < MAX_AVAILABLE; ++i) {
if (!used[i]) {
used[i] = true;
return items[i];
}
}
return null; // not reached
}
protected synchronized boolean markAsUnused(Object item) {
for (int i = 0; i < MAX_AVAILABLE; ++i) {
if (item == items[i]) {
if (used[i]) {
used[i] = false;
return true;
} else
return false;
}
}
return false;
}
}
在获取项目之前,每个线程必须从信号量获取许可,保证有可用的项目。当线程使用完项目时,它将返回池中,并返回一个许可给信号量,允许另一个线程获取该项目。注意,在调用 acquire 时不会保持同步锁定,因为这会阻止将项目返回池中。信号量封装了限制访问池所需的同步,与维护池本身一致性所需的同步分开。
一个初始化为 1 的信号量,并且在使用时最多只有一个许可可用,可以用作互斥锁。这通常被称为二进制信号量,因为它只有两种状态:一个许可可用,或零许可可用。使用此方法时,二进制信号量具有以下属性(与许多 java.util.concurrent.locks.Lock 实现不同):"锁"可由非所有者线程释放(因为信号量没有所有权的概念)。这在一些特殊的情况下很有用,例如死锁恢复。
这个类的构造函数可选地接受一个公平性参数。当设为 false 时,此类不保证线程获取许可的顺序。特别是,允许贡献,即,调用 acquire 的线程可以在等待的线程前面分配许可 - 逻辑上,新线程将自己放在等待线程的队列的头部。当公平性设置为 true 时,信号量保证调用任何 acquire 方法的线程按照处理这些方法调用的顺序(先进先出;FIFO)来选择获取许可。注意,FIFO 排序必须适用于这些方法内部的特定执行点。因此,一个线程可能在另一个线程之前调用 acquire,但在另一个线程之后到达排序点,并且在从方法返回时类似。另请注意,未定时的 tryAcquire 方法不遵守公平性设置,但会拿走所有可用的许可。
通常,用于控制资源访问的信号量应被初始化为公平的,以确保没有线程因访问资源而被挤出。在使用信号量进行其他类型的同步控制时,非公平排序的吞吐量优势通常超过了公平性考虑。
此类还提供了在一次获取和释放多个许可的便捷方法。这些方法通常比循环更有效率和更有效。但是,它们不建立任何优先顺序。例如,如果线程 A 调用 s.acquire(3)和线程 B 调用 s.acquire(2),并且两个许可变为可用,则除非 B 的 acquire 首先进行,否则没有保证 B 将获得它们,除非信号量 s 处于公平模式。 内存一致性效果:调用“release”方法(例如 release())之前的线程中的操作在另一个线程中成功调用“acquire”方法(例如 acquire())之后的操作之前发生。
总的来说就是根据信号量维护的许可来陪护线程的同步,底层控制依旧是AQS
protected int tryAcquireShared(int acquires) {
for (;;) {
//判断是否有队列前区,公平与非公平的区别,公平有队列前驱的情况下直接会加入队列
if (hasQueuedPredecessors())
return -1;
int available = getState();
//剩余量=可用-当前获取的
int remaining = available - acquires;
if (remaining < 0 ||
compareAndSetState(available, remaining))
return remaining;
}
}
//释放共享锁,释放的时候是做加法,所以即使最开始设置的许可是0,也能释放成功
protected final boolean tryReleaseShared(int releases) {
for (;;) {
int current = getState();
int next = current + releases;
if (next < current) // overflow
throw new Error("Maximum permit count exceeded");
if (compareAndSetState(current, next))
return true;
}
}
用例
public class SemaphoresExample {
private Semaphore semaphoresA = new Semaphore(1);
private Semaphore semaphoresB = new Semaphore(0);
private Semaphore semaphoresC = new Semaphore(0);
public static void main(String[] args) {
SemaphoresExample example = new SemaphoresExample();
ExecutorService service = Executors.newFixedThreadPool(3);
service.execute(example.new RunnableA());
service.execute(example.new RunnableB());
service.execute(example.new RunnableC());
service.shutdown();
}
private class RunnableA implements Runnable {
public void run() {
for (int i = 0; i < 10; i++) {
try {
semaphoresA.acquire();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println(String.format("第%d遍", i + 1));
System.out.println("A");
semaphoresB.release();
}
}
}
private class RunnableB implements Runnable {
public void run() {
for (int i = 0; i < 10; i++) {
try {
semaphoresB.acquire();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("B");
semaphoresC.release();
}
}
}
private class RunnableC implements Runnable {
public void run() {
for (int i = 0; i < 10; i++) {
try {
semaphoresC.acquire();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("C");
System.out.println();
semaphoresA.release();
}
}
}
}
//output
第1遍
A
B
C
第2遍
A
B
C
...
第10遍
A
B
C
ForkJoinPool
概述
ForkJoinPool 是一个用于运行 ForkJoinTask 的 ExecutorService。ForkJoinPool 提供了非 ForkJoinTask 客户端提交任务的入口,以及管理和监控操作。 ForkJoinPool 与其他类型的 ExecutorService 主要不同之处在于它使用工作窃取:池中的所有线程都尝试找到并执行提交给池的任务和/或由其他活动任务创建的任务(如果不存在任务则最终阻塞等待工作)。当大多数任务生成其他子任务(如大多数 ForkJoinTask)时,以及当许多小任务从外部客户端提交到池中时,这样做可以实现高效处理。特别是在构造函数中将 asyncMode 设置为 true 时,ForkJoinPools 也可能适用于永远不被合并的事件风格任务。所有工作线程都被初始化为 Thread.isDaemon 设置为 true。
一个静态的commonPool()通常适用于大多数应用程序。任何未明确提交到指定池的ForkJoinTask都使用公共池。使用公共池通常会减少资源使用(其线程在不使用时会慢慢回收, 并在随后使用时重新启用)。 对于需要独立或自定义池的应用程序, 可以使用给定的并行目标水平构造ForkJoinPool; 默认情况下, 等于可用处理器数量。该池试图通过动态添加、挂起或恢复内部工作线程来维护足够的活动(或可用)线程, 即使某些任务在等待加入其他任务时阻塞。然而, 面对阻塞的I / O或其他未管理的同步, 没有保证进行任何调整。内嵌的ForkJoinPool.ManagedBlocker接口可以扩展同步的种类。默认策略可以使用与类ThreadPoolExecutor中文档对应的参数覆盖。
除了执行和生命周期控制方法外, 此类还提供状态检查方法(例如getStealCount), 旨在帮助开发、调整和监控fork / join应用程序。此外, toString方法以方便的形式返回池状态的指示, 以便进行非正式监控。 与其他ExecutorServices一样, 以下表总结了三种主要的任务执行方法。这些方法主要用于不在当前池中进行fork / join计算的客户端。这些方法的主要形式接受ForkJoinTask的实例, 但重载形式也允许混合执行基于普通Runnable或Callable的活动。然而, 已经在池中执行的任务通常应该使用表中列出的计算内形式, 除非使用不通常联合的异步事件风格任务, 在这种情况下, 方法的选择几乎没有差别。

构造常见池的参数可以通过设置以下系统属性来控制:
java.util.concurrent.ForkJoinPool.common.parallelism - 并行性级别, 非负整数
java.util.concurrent.ForkJoinPool.common.threadFactory - ForkJoinPool.ForkJoinWorkerThreadFactory的类名。系统类加载器用于加载此类。
java.util.concurrent.ForkJoinPool.common.exceptionHandler - Thread.UncaughtExceptionHandler的类名。系统类加载器用于加载此类。 java.util.concurrent.ForkJoinPool.common.maximumSpares - 保持目标并行性的允许的最大额外线程数(默认为256)。
如果未通过系统属性提供线程工厂, 则公共池使用一个工厂, 该工厂使用系统类加载器作为线程上下文类加载器。此外, 如果存在安全管理器, 则公共池使用一个工厂提供没有权限启用的线程。在建立这些设置的任何错误时, 将使用默认参数。通过将并行性属性设置为零, 并/或使用可能返回null的工厂来禁用或限制公共池中的线程的使用是可能的。然而, 这样做可能导致未加入的任务永远不会被执行。 实现说明: 此实现将最大运行线程数限制为32767。试图创建大于最大数量的池将导致IllegalArgumentException。 当池关闭或内部资源耗尽时, 此实现会拒绝提交的任务(即, 通过抛出RejectedExecutionException)。
ForkJoinPool 实现概述:
这个类和它的内嵌类提供了一组工作线程的主要功能和控制: 非 FJ 线程的提交会进入提交队列。工作线程取走这些任务,通常将它们分成子任务,可能被其他工作线程抢走。基于随机扫描的工作窃取通常导致比 "工作处理" 更好的吞吐量,其中生产者分配任务给空闲线程,因为在信号线程醒来之前完成其他任务的线程(这可能是很长的时间)可以接手该任务。优先级规则优先处理来自自己队列(LIFO 或 FIFO,取决于模式)的任务,然后是对其他队列任务的随机 FIFO 窃取。这个框架最初是支持使用工作窃取的树形并行的载体。随着时间的推移,它的可扩展性优势导致了扩展和变化,以更好地支持更多不同的使用场景。因为大多数内部方法和内嵌类是相互关联的,所以它们的主要原理和描述在这里呈现;单独的方法和内嵌类只包含有关细节的简短评论。
- WorkQueues
- ==========
大部分操作都发生在工作窃取队列(在嵌套类 WorkQueue 中)中。这些是 Deques 的特殊形式,仅支持四个可能的端点操作中的三个:push,pop 和 poll(也称为 steal),在更进一步的约束条件下:push 和 pop 只能从拥有线程(或者,如此扩展的话,在锁下)调用,而 poll 可以从其他线程调用。(如果您不熟悉它们,则可能需要先阅读 Herlihy 和 Shavit 的《多处理器编程艺术》一书,第 16 章更详细地描述这些,然后再继续)。主要的工作窃取队列设计与 Chase 和 Lev 的 SPAA 2005 论文“Dynamic Circular Work-Stealing Deque”(http://research.sun.com/scalable/pubs/index.html)和 Michael,Saraswat 和 Vechev 的 PPoPP 2009 论文“Idempotent work stealing”(http://portal.acm.org/citation.cfm?id=1504186)中的队列大致相似。最终的主要差异来自 GC 的要求,即我们尽早地把已取的插槽置为空,以便在生成大量任务的程序中保持尽可能小的占用空间。为了实现这一点,我们将 CAS 从指示 pop 与 poll(steal)的索引(“base”和“top”)转移到了插槽本身。
添加任务的形式就是在循环缓冲区中执行经典数组 push(task):
q.array[q.top++ % length] = task;
实际代码需要进行 null-check 和 size-check,
在索引 2 的幂次大小的数组中使用 masking 而不是 mod,
强制执行内存排序,支持重新调整大小,并可能
信号等待工作者开始扫描 -- 见下文。
pop 操作(总是由所有者执行)的形式为:
if ((task = getAndSet(q.array, (q.top-1) % length, null)) != null)
decrement top and return task;
如果失败,队列为空。
另一个偷窃者线程的 poll 操作基本上是:
if (CAS nonnull task at q.array[q.base % length] to null)
increment base and return task;
该尝试可能因为争用而失败,并可能被重试。实现必须在尝试CAS之前确保基础索引和任务的一致快照(通过循环或尝试其他地方)。实际上并没有这样的方法,因为由于不一致或争用导致的失败在不同的上下文中以不同的方式处理,通常首先尝试其他队列(最简单的例子请参见方法pollScan)。对于需要在提取元素之前检查元素的情况,还有其他变体,因此必须与此代码的变体交替使用。此外,更高效的版本(nextLocalTask)用于拥有者的调查。它避免了一些开销,因为在调用期间队列不能增长。
内存排序。请参考Le, Pop, Cohen, and Nardelli在PPoPP 2013上发表的“Correct and Efficient Work-Stealing for Weak Memory Models”(http://www.di.ens.fr/~zappa/readings/ppopp13.pdf),了解与这里使用的工作窃取算法类似的内存排序要求的分析。通过使用volatile或原子访问或显式栅栏将任务插入数组槽或从数组槽中提取任务提供主要同步。
对双端队列元素的操作需要读写索引和槽。当可能时,我们允许它们以任意顺序进行。由于基础和顶部索引(以及其他在许多方法中访问的池或数组字段)仅仅不精确地指导提取数据的位置,因此我们允许除了元素getAndSet / CAS / setVolatile以外的访问以任意顺序出现,使用普通模式。但是,我们仍然必须在许多方法(主要是可能被外部访问的方法)的前面加上acquireFence以避免无限的过时。这相当于好像调用者在调用方法时使用了对池或队列的引用的获取读取,即使它们没有。当需要获取模式但不是由上下文保证时,我们使用显式获取读取(getSlot)而不是普通数组访问。为了减少其他窃取者的滞留,我们鼓励立即更新基础索引的写入,并立即在更新之后写入必须更新的volatile字段,或者如果没有这样的机会,则写入不透明模式写入。
因为索引和槽内容不能始终保持一致,所以空性检查 base == top 仅在静止状态下是准确的(因此在此情况下使用)。否则,它可能偏向于可能使队列看起来非空,当push,pop或poll尚未完全提交,或使其看起来为空,当top或base的更新尚未被看到时。类似地,在push中检查队列数组已满可能在未完全满时触发,导致比所需时间早的调整大小。
因为槽与索引可能不一致,所以单独考虑时,poll操作不是无阻塞的。在一个in-progress的poll(或者在队列为空时的push)可见完成之前,一个盗贼不能成功继续。如果试图偷窃失败,扫描盗贼将选择不同的目标来尝试下一步。因此,为了让一个盗贼进展,只需要任何正在进行的poll或任何空队列上的新push完成即可。最坏情况发生在许多线程正在寻找由滞留的生产者生产的任务时。
这种方法还可以支持以FIFO(先进先出)而不是LIFO(后进先出)顺序处理任务的用户模式,只需使用poll而不是pop。这在任务永远不会被加入的消息传递框架中是有用的,尽管在任务生产者和消费者之间竞争增加。
WorkQueues也用于提交给池的任务的类似方式。我们不能混合使用工人使用的任务队列。相反,我们使用一种哈希的形式随机将提交队列与提交线程相关联。ThreadLocalRandom探针值用作选择现有队列的哈希码,在与其他提交者发生冲突时可能随机重新定位。本质上,提交者的行为与工人类似,但他们只能执行他们提交的本地任务(或已知的子任务)。共享模式下的任务插入需要锁定。我们只使用简单的自旋锁(使用字段“source”),因为遇到忙队列的提交者会移动到不同的位置以使用或创建其他队列。他们只在注册新队列时阻塞。
管理 ==========
工作窃取的主要吞吐量优势来自于分散控制 - 工人主要从自己或彼此那里获取任务,速率可以超过每秒10亿次。大多数非原子控制是通过一些形式的队列扫描来完成的。该池本身创建、激活(启用任务的扫描和运行)、停用、阻塞和终止线程,都只需要最少的中心信息。我们只能跟踪或维护很少的属性,因此我们将它们打包到少数变量中,通常不需要阻塞或锁定就可以保持原子性。几乎所有本质上的原子控制状态都保存在几个易失性变量中,这些变量最常读取(而不是写入)作为状态和一致性检查。我们在其中尽可能多地塞入信息。
字段“ctl”包含64位信息,用于原子决策添加、入队(在事件队列上)和出队和释放工作者。为了实现此打包,我们将最大并行性限制为(1<<15)-1(远高于正常操作范围),以允许标识、计数及其否定(用于阈值)适合16位子字段。 * 字段“mode”保存配置参数以及生命周期状态,通过位运算原子且单调设置SHUTDOWN、STOP,最后是TERMINATED位。它仅通过位运算原子(getAndBitwiseOr)进行更新。
数组 "queues" 存储了 WorkQueues 的引用。它在注册锁的保护下进行更新(仅在工作线程创建和终止时),但是可以并发读取,直接访问(虽然总是在 acquireFences 或其他获取读取之前)。为了简化基于索引的操作,数组大小始终是2的幂,所有读者都必须容忍空槽。工作者队列在奇数索引处。工作者 ID 与其索引进行掩码匹配。共享(提交)队列在偶数索引处。将它们分在一起可以简化和加速任务扫描。
所有工作线程的创建都是按需创建,由任务提交、已终止工作线程的替换和/或阻塞工作线程的补偿触发。然而,所有其他支持代码都是配置为按照其他政策工作的。为了确保不持有阻止GC的工作线程或任务引用,对WorkQueues的所有访问都是通过队列数组的索引进行的(这是一些混乱代码构造的一个来源)。本质上,队列数组充当弱引用机制。因此,例如,ctl的堆栈顶部子字段存储索引,而不是引用。
不同于高性能计算的工作窃取框架,当立即找不到任务时,我们不能让工作者不断扫描任务,也不能在有任务可用时启动/恢复工作者。另一方面,当提交或生成新任务时,我们必须迅速地唤醒他们。这些延迟主要取决于JVM park/unpark(和底层OS)性能,这可能很慢且不稳定。在许多用途中,启动时间是总体性能的主要限制因素,在程序启动时由JIT编译和分配加剧。另一方面,当太多线程为太少任务进行投票时,吞吐量会降低。
"ctl" 字段使用原子操作维护总工作线程数和 "released" 工作线程数,以及可用工作线程队列(实际上是栈,由 ctl 的低 32 位子字段表示)的头。已知正在扫描任务并/或运行任务的工作线程是 "released" 工作线程。未发布("可用")的工作线程记录在 ctl 栈中。这些工作线程可以通过入队列在 ctl 中(请参阅方法 awaitWork)进行信号。 "队列" 是 Treiber 栈的一种形式。这对于以最近使用的顺序激活线程是理想的,提高了性能和局部性,超过了易受争议和不能释放工作线程(除非它在栈顶)的缺点。栈顶状态保存工作线程的 "phase" 字段的值:其索引和状态,以及版本计数器,除了计数子字段(也用作版本戳)外,提供对 Treiber 栈 ABA 效应的保护。
创建工作线程。为了创建工作线程,我们先增加计数(作为预定),并试图通过其工厂构造一个ForkJoinWorkerThread。在启动时,新线程首先调用registerWorker,在那里它构造了一个WorkQueue,并分配了队列数组中的索引(如果需要,则扩展数组)。如果工厂返回空,池继续运行,但数量少于目标数量的工作线程。如果出现异常,则异常被传播,通常是一些外部调用者。
工作队列字段“phase”既由工作线程和池管理,也用于跟踪工作线程是否为UNSIGNALLED(可能因等待信号而阻塞)。当工作线程被排队时,其phase字段被设置为负数。请注意,phase字段更新滞后于队列CAS释放;看到负数phase并不保证工作线程可用。当排队时,其低16位的phase必须保存其池索引。因此,我们在初始化时将索引放在那里,并且永远不会修改这些位。
"ctl"字段同时也是围绕激活的内存同步的基础。这里使用了一个更高效的 Dekker 规则的版本,任务生产者和消费者通过写入/CASing ctl 来进行同步(即使对于不需要操作的常见情况)。然而,与常见情况下CASing ctl到其当前值不同,我们通过确保signalWork调用是在全可 volatile 内存访问之前进行的(通常也需要)来减少写入冲突。
信号。信号(在 signalWork 中)导致新的或再激活的工作者扫描任务。方法 signalWork 及其调用者试图估计无法实现的目标,即为任务激活合适数量的工作者,但必须偏向于激活过多工作者而不是过少以避免阻塞。如果计算纯粹是树形结构,则当工作者将任务推入空队列时,每个工作者都应激活另一个工作者,从而在 O(log(#threads)) 步内完全激活。如果任务是从单个生产者连续输入的,则每个工作者在从队列中取出其第一个(上次静态后)任务时,如果该队列中还有更多任务,应该向另一个工作者发送信号。这等同于,但通常比安排偷窃者取两个任务,再将其中一个推回自己的队列并发送信号(因为其队列为空)更快,也导致对数时间全部激活。因为我们不知道使用模式(或最常见的混合),我们使用两种方法。我们通过安排 scan() 中的工作者在重复从任何给定队列中取出任务时不重复发送信号,通过记住之前的任务来近似第二条规则。在两个规则都可以适用的窄窗口中,可能会导致重复或不必要的信号。尽管存在这样的限制,但通常这些规则可以避免当工人争夺任务太少,或生产者浪费大部分时间重新信号时发生的减速。然而,在启动,关闭和仅涉及少数工人的小计算中,仍可能发生争夺和开销效应。
扫描。scan方法执行顶层任务的扫描(和执行)。不同工人和/或在不同时间的扫描不太可能以相同的顺序轮询队列。每次扫描遍历并试图从以伪随机排列顺序的每个队列轮询,从随机索引开始,并使用恒定的循环详尽步幅;在竞争时重新开始。(非顶层扫描;例如在helpJoin中,使用更简单的线性探测,因为它们不会与顶层扫描系统地竞争。)伪随机生成器不需要长期具有高质量的统计属性。我们使用用ThreadLocalRandom探测中的Weyl序列种子的Marsaglia XorShifts,这是便宜的,足够。扫描未明确考虑核心亲和性、负载、缓存局部性等,但它们通过偏爱在成功的轮询后从相同的队列重新轮询(在方法topLevelExec中查看)来利用时间局部性(通常近似这些)。这减少了公平性,这部分被使用可能丢失给其他工人的一次性轮询(tryPoll)所抵消。
Deactivation. 当没有任务被发现时,scan方法返回一个哨兵,导致停用(请参见awaitWork)。ctl中的count字段允许精确发现静止状态(即,当所有工作者都处于空闲状态时)在停用后。然而,这也可能与新的(外部)提交竞争,因此还需要再次检查以确定静止状态。在明显触发静止状态时,awaitWork重新扫描并自我信号,如果它可能错过了信号。在其他情况下,错过的信号可能短暂降低并行性,因为停用并不意味着没有更多的工作,只是没有其他工作者接受的任务。但是(请参见上面)会生成更多的信号以在需要时重新激活。
Trimming workers. 为了在使用不足时释放资源,当池处于静止状态时开始等待的工作者将超时并终止,如果池保持静止状态的时间超过了由keepAlive字段给出的时间段。
关闭和终止。 调用 shutdownNow 会调用 tryTerminate 来原子地设置一个模式位。 调用线程和每个其他工作线程在终止时都将帮助终止其他线程,通过取消它们未处理的任务并唤醒它们。 调用不突然的 shutdown() 在触发终止的“STOP”阶段之前先检查 isQuiescent。 为了符合 ExecutorService invoke,invokeAll 和 invokeAny 规范,我们必须在等待期间跟踪池状态,并在终止时中断可中断的调用者 (请参阅 ForkJoinTask.joinForPoolInvoke 等)。
合并任务
通常,在一个任务未完成时加入任务的第一选择是从本地队列中分离出它并运行它。否则,当一个工作者等待加入另一个工作者抢夺(或始终持有)的任务时,可以采取多种操作。因为我们正在将许多任务复用到工作者池上,我们不能总是让它们阻塞(就像Thread.join)。我们也不能只是用另一个替换加入者的运行时堆栈,并稍后替换它,这是一种形式的“继续”,即使可能也不一定是好的,因为我们可能需要一个解锁的任务和它的继续才能进展。相反,我们结合了两种策略:
-
帮助:安排加入者执行一些任务,如果不偷取它们它可以正在运行。
-
补偿:除非已经有足够的活线程,tryCompensate()方法可以创建或重新激活一个备用线程,以补偿被阻塞的加入者,直到它们解锁。
第三种形式(通过tryRemove实现)相当于帮助假设的补偿者:如果我们可以很容易地确定补偿者的可能行动是窃取并执行正在加入的任务,则加入线程可以直接这样做,而不需要补偿线程;尽管存在队列数组存在瞬态差距的(罕见的)可能性导致并行性降低。
其他特定任务类型的中间形式(例如helpAsyncBlocker)通常避免或推迟阻塞或补偿的需要。
ManagedBlocker扩展API不能使用帮助,因此仅在awaitBlocker方法中依赖补偿。
helpJoin 算法实现了一种线性帮助形式。
每个工作线程都会记录 (在字段 "source" 中) 它最后从哪个队列偷取任务的 ID。helpJoin 方法中的扫描使用这些标记,试图找到一个工作线程来帮助(即从中偷取任务并执行),以加快正在加入的任务的完成。因此,加入者执行一个任务,如果没有待加入的任务,它应该在自己的本地双端队列上。这是 Wagner & Calder "Leapfrogging: a portable technique for implementing efficient futures" SIGPLAN Notices, 1993 (http://portal.acm.org/citation.cfm?id=155354) 中描述的方法的保守变体。主要的不同在于我们只记录队列 ID,而不是完整的依赖关系链接。这需要对队列数组进行线性扫描,以定位偷窃者,但是成本仅在需要时才被隔离,而不是增加每个任务的开销。此外,搜索仅限于直接的,最多两层间接的偷窃者,此后,开销的增加就会急剧减少。当搜索记录源被停滞时,可能找不到偷窃者。此外,即使精确识别,偷窃者也可能永远不会产生加入者可以帮助的任务。因此,当无法找到可运行的任务时,将尝试补偿。
加入 CountedCompleters(参见 helpComplete)与其他情况的不同之处在于,任务的资格是通过检查完成链而不是跟踪窃取者来确定的,并且通常更有效。
在超时(ForkJoinTask 定时 get)下加入使用了一种受限制的帮助和补偿的混合物,部分原因是池(实际上,只有公共池)可能没有任何可用的线程:如果池被饱和(所有可用的工作者都忙碌),调用者尝试删除和其他帮助;否则,它会在补偿下阻塞,以便它可以独立于任何任务超时。
默认情况下,补偿不旨在在任何特定时刻保持目标并行度数量的未阻塞线程运行。这个类的一些以前的版本对于任何阻塞的加入都采用立即补偿。然而,实际上,绝大多数阻塞都是由于GC和其他JVM或OS活动造成的暂时性副产品,如果它们导致超配置时间更长,它们会变得更劣。我们允许用户覆盖只在明显饥饿时增加线程的默认行为,而不是强加任意政策。补偿机制也可以有限制。通用池(请参见COMMON_MAX_SPARES)的界限有助于JVM在资源耗尽前应对编程错误和滥用。
通用池
===========
通用池在静态初始化后始终存在。由于它(或其他任何创建的池)不需要使用,因此我们将初始化的开销和代价最小化为大约十二个字段的设置。
当外部线程向通用池提交时,它们可以在合并时执行子任务处理(请参阅helpComplete和相关方法)。这种调用方帮助的政策使得将通用池的并行性设置为少于可用核心总数的一个(或更多),甚至为纯调用者运行设置为零是合理的。我们不需要记录外部提交是否是到通用池-如果不是,外部帮助方法将快速返回。这些提交者否则会在等待完成时被阻塞,因此在不适用的情况下额外的努力(加上大量的任务状态检查)相当于ForkJoinTask.join在阻塞之前的有限的自旋等待的奇怪形式。
对于公共池中的并行度为零的保证仅限于以树状结构被其调用者加入或使用 CountedCompleters 的任务(就像 jdk parallelStreams 一样)。支持渗透到多个方法,包括那些在没有工人的情况下重试帮助步骤,直到确信不适用。
在管理的环境中,除非被系统属性覆盖,当存在 SecurityManager 时,我们使用 InnocuousForkJoinWorkerThread 的工人作为更合适的默认值。这些工人没有权限设置,不属于任何用户定义的 ThreadGroup,在执行任何顶级任务后擦除所有 ThreadLocals。相关机制可能是 JVM 依赖的,必须访问特定的 Thread 类字段才能实现此效果。
中断处理
框架被设计为独立于运行任务的线程的中断状态管理任务取消(ForkJoinTask.cancel)。 (有关基本原理,请参阅公共ForkJoinTask文档。)只在tryTerminate中发出中断,当工人应该终止时,任务应该被取消。 仅在必要时清除中断,以确保LockSupport.park调用不会无限循环(如果当前线程被中断,park立即返回)。 如果是这样,则在阻塞后重新恢复中断,如果在任何任务范围内可以看到状态。 对于指定任务体或希望在取消时中断的情况,可以覆盖ForkJoinTask.cancel以进行此操作(就像在invoke {Any,All}中所做的那样)。
内存布局
ForkJoinPool 和 WorkQueues 实例以及它们的队列数组的放置对性能非常敏感。为了减少虚假共享的影响,@Contended 注释隔离了 ForkJoinPool.ctl 字段以及最频繁写入的 WorkQueue 字段。这些主要通过扫描器减少了缓存流量。 WorkQueue 数组的预设大小足够大,可以避免在大多数树状计算中调整大小(虽然在一些流式使用中不是这样),但当队列靠近内存中的其他位置时,大小不足以避免二次竞争效应(特别是对于 GC 卡标)。这很常见,但在不同的收集器中有不同的影响,并且仍然不完全解决。
样式说明
内存排序主要依赖原子操作(CAS、getAndSet、getAndAdd)和显式栅栏。 这可能是笨拙和丑陋的,但也反映了在具有非常少的不变量的非常比赛代码中控制结果的需求。 在使用之前,所有字段都读入本地,并在引用时检查是否为null,即使在当前使用下永远不为null。 使用masked索引的数组访问包括检查(始终为真)数组长度非零,以避免编译器插入更昂贵的陷阱。 这通常采用类似“C”的样式,在方法或块的头部列出声明,并在第一次遇到时使用内联赋值。 几乎所有显式检查都导致绕过/返回,而不是异常抛出,因为它们在关闭期间可能合法地出现。
类ForkJoinPool、ForkJoinWorkerThread和ForkJoinTask之间存在很多表示层的耦合。
WorkQueue的字段维护由ForkJoinPool管理的数据结构,因此直接访问。
减少这种情况没有多大意义,因为任何相关的表示更改都将需要伴随着算法更改。
许多方法因为必须累积存储在本地变量中的字段的一组一致读取而显得臃肿。
其他一些方法是人为分裂的,以减少动态编译造成的生产者/消费者失衡。
还有其他一些奇怪的编码(包括几个看起来不必要的升级空检查),帮助一些方法在解释时(而不是编译)表现出合理的性能。
这个文件中声明的顺序是(有一些例外):
(1)静态实用程序函数
(2)嵌套(静态)类
(3)静态字段
(4)字段,以及解压缩其中一些字段时使用的常量
(5)内部控制方法
(6)回调和其他支持ForkJoinTask方法的支持
(7)导出方法
(8)静态块以最小依赖顺序初始化静态内容
修订说明
2020年1月ForkJoin类的主要差异来源如下: * * * ForkJoinTask现在使用字段"aux"支持阻塞合并和/或记录异常,取代对内置监视器和辅助表的依赖。
* * 扫描探针槽(与比较索引相比),以及与此相关的改变,减少了跨越大多数垃圾回收器的性能差异,并减少了竞争。
* * 重构以更好地整合特殊任务类型和其他功能,这些功能已经逐步加入。此外,还有许多小的修整,以提高一致性。
CopyOnWriteArrayList
概述
CopyOnWriteArrayList是一种线程安全的ArrayList变体,所有的可变操作(如增加、设置等)都通过创建基础数组的新副本来实现。通常这样做成本太高,但是在遍历操作数量远大于修改操作的情况下可能比其他方法更高效,当你不能或不想同步遍历时特别有用,同时也需要防止多个并发线程之间的干扰。"快照"样式的迭代器方法使用对迭代器创建时数组状态的引用。此数组在迭代器的生命周期内不会更改,因此干扰是不可能的,并且迭代器保证不会抛出ConcurrentModificationException。迭代器不会反映自迭代器创建以来的列表中的添加、删除或更改。不支持迭代器本身上的元素更改操作(删除、设置和添加)。这些方法会抛出UnsupportedOperationException。允许所有元素,包括空。内存一致性效果: 与其他并发集合一样,线程中在将对象放入CopyOnWriteArrayList之前的操作对于另一个线程中访问或删除该元素的操作具有happen-before关系。
源码解析
public void add(int index, E element) {
//添加时先加锁
synchronized (lock) {
Object[] es = getArray();
int len = es.length;
if (index > len || index < 0)
throw new IndexOutOfBoundsException(outOfBounds(index, len));
Object[] newElements;
int numMoved = len - index;
//如果不需要移动
if (numMoved == 0)
newElements = Arrays.copyOf(es, len + 1);
else {
//已添加的位置分开,做两次拷贝,避免元素移动开销
newElements = new Object[len + 1];
System.arraycopy(es, 0, newElements, 0, index);
System.arraycopy(es, index, newElements, index + 1,
numMoved);
}
newElements[index] = element;
//将原容器引用指向新副本
setArray(newElements);
}
}
//get方法直接获取,不需要加锁
public E get(int index) {
return elementAt(getArray(), index);
}
static <E> E elementAt(Object[] a, int index) {
return (E) a[index];
}
boolean bulkRemove(Predicate<? super E> filter, int i, int end) {
// assert Thread.holdsLock(lock);
final Object[] es = getArray();
// Optimize for initial run of survivors
for (; i < end && !filter.test(elementAt(es, i)); i++)
;
if (i < end) {
final int beg = i;
final long[] deathRow = nBits(end - beg);
int deleted = 1;
deathRow[0] = 1L; // set bit 0
for (i = beg + 1; i < end; i++)
if (filter.test(elementAt(es, i))) {
setBit(deathRow, i - beg);
deleted++;
}
// Did filter reentrantly modify the list?
if (es != getArray())
throw new ConcurrentModificationException();
final Object[] newElts = Arrays.copyOf(es, es.length - deleted);
int w = beg;
for (i = beg; i < end; i++)
if (isClear(deathRow, i - beg))
newElts[w++] = es[i];
System.arraycopy(es, i, newElts, w, es.length - i);
setArray(newElts);
return true;
} else {
if (es != getArray())
throw new ConcurrentModificationException();
return false;
}
}
// A tiny bit set implementation
// long[]的每一位代表着一个bit set的元素
private static long[] nBits(int n) {
// long占64=2^6位,故n个元素需要((n - 1) >> 6) + 1个long
return new long[((n - 1) >> 6) + 1];
}
private static void setBit(long[] bits, int i) {
// 1L << i == 1L << (i%64)
bits[i >> 6] |= 1L << i;
}
private static boolean isClear(long[] bits, int i) {
return (bits[i >> 6] & (1L << i)) == 0;
}
CompletionStage
概述
CompletableFuture 是一个Future, 可以显式地完成(设置其值和状态), 并且可以用作CompletionStage, 支持依赖函数和在完成时触发的动作。 当两个或更多的线程尝试完成, completeExceptionally或取消CompletableFuture时, 只有其中一个成功。 除了这些和相关的直接操纵状态和结果的方法外, CompletableFuture还实现了以下策略的接口CompletionStage:
- 对于非异步方法的依赖完成提供的操作可能由完成当前 CompletableFuture 的线程或完成方法的任何其他调用者执行。
- 所有没有显式 Executor 参数的 async 方法都使用 ForkJoinPool.commonPool() 执行(除非它不支持至少两个并行级别,在这种情况下,将创建一个新线程来运行每个任务)。这可以在子类中通过定义 defaultExecutor() 方法来覆盖非静态方法。为简化监视,调试和跟踪,所有生成的异步任务都是 CompletableFuture.AsynchronousCompletionTask 标记接口的实例。具有延迟的操作可以使用此类中定义的适配器方法,例如:supplyAsync(supplier, delayedExecutor(timeout, timeUnit))。为了支持具有延迟和超时的方法,此类最多维护一个守护线程来触发和取消操作,而不是运行它们。
- 所有CompletionStage方法都是独立于其他公共方法实现的,因此一个方法的行为不会受到子类中其他方法重写的影响。
- 所有CompletionStage方法都返回CompletableFuture。要限制仅使用接口CompletionStage中定义的方法,请使用minimalCompletionStage方法。或者确保客户端不会自己修改未来,请使用copy方法。
CompletableFuture 同时实现了 Future 接口,并遵循以下策略。
- 因为(与FutureTask不同)这个类没有直接控制导致它完成的计算, 所以取消会被视为另一种特殊完成方式。cancel方法与completeExceptionally(new CancellationException())效果相同。isCompletedExceptionally方法可用于确定CompletableFuture是否以任何特殊方式完成。
- 这个类在异常完成时使用CompletionException,get()和get(long, TimeUnit)方法会抛出一个ExecutionException,其原因与CompletionException中所持有的相同。为了简化大多数上下文中的使用,这个类还定义了join()和getNow方法,在这些情况下直接抛出CompletionException。
在使用方法接受它们时用来传递完成结果的参数(即类型为T的参数)可能为空,但是为任何其他参数传递空值将导致抛出NullPointerException。 这个类的子类通常应该重写“虚拟构造函数”方法newIncompleteFuture,它确定了CompletionStage方法返回的具体类型。例如,这里有一个类替换了不同的默认执行程序并禁用了obtrude方法:
class MyCompletableFuture<T> extends CompletableFuture<T> {
static final Executor myExecutor = ...;
public MyCompletableFuture() { }
public <U> CompletableFuture<U> newIncompleteFuture() {
return new MyCompletableFuture<U>(); }
public Executor defaultExecutor() {
return myExecutor; }
public void obtrudeValue(T value) {
throw new UnsupportedOperationException(); }
public void obtrudeException(Throwable ex) {
throw new UnsupportedOperationException(); }
}
ScheduledExecutorService
概述
ScheduledExecutorService是一种可以在给定延迟后调度命令运行,或周期性执行命令的ExecutorService。schedule 方法创建具有不同延迟的任务,并返回一个可用于取消或检查执行的任务对象。scheduleAtFixedRate 和 scheduleWithFixedDelay 方法创建并执行周期性运行直到取消的任务。使用 Executor.execute(Runnable) 和 ExecutorService submit 方法提交的命令将使用零延迟进行调度。schedule 方法允许使用相对延迟和周期作为参数,而不是绝对时间或日期。将 java.util.Date 表示的绝对时间转换为所需格式是很简单的事情。例如,要在某个将来的日期安排任务,可以使用:schedule(task, date.getTime() - System.currentTimeMillis(), TimeUnit.MILLISECONDS)。然而,请注意,由于网络时间同步协议,时钟偏差或其他因素,相对延迟的到期可能不会与任务启用时的当前日期重合。Executors 类提供了本包中提供的 ScheduledExecutorService 实现的方便的工厂方法。
源码解析
提交一个单次任务,在给定延迟后启用。
参数: command – 要执行的任务 delay – 从现在开始延迟执行的时间 unit – 延迟参数的时间单位
返回: 一个 ScheduledFuture,表示任务尚未完成,其 get() 方法在完成后将返回 null。
public ScheduledFuture<?> schedule(Runnable command,long delay, TimeUnit unit);
提交一个带返回值的单次任务,在给定延迟后启用。
参数: callable – 要执行的函数 delay – 从现在开始延迟执行的时间 unit – 延迟参数的时间单位
类型参数: <V> – callable 的结果类型
返回: 一个 ScheduledFuture,可用于提取结果或取消。
public <V> ScheduledFuture<V> schedule(Callable<V> callable,long delay, TimeUnit unit);
提交一个周期性任务,在给定的初始延迟后首先启用,然后按照给定的周期进行; 也就是说,执行将在 initialDelay 后开始,然后是 initialDelay + period,然后是 initialDelay + 2 * period,以此类推。 任务执行序列将无限期地继续下去,直到发生以下异常完成之一: 任务通过返回的 future 明确取消。 执行器终止,这也导致任务取消。 任务的执行抛出异常。在这种情况下,调用返回的 future 的 get 将抛出 ExecutionException,并将该异常作为其原因。 后续执行被禁止。返回的 future 的后续 isDone() 调用将返回 true。 如果此任务的任何执行时间超过其周期,则后续执行可能会延迟,但不会并发执行。
参数: command – 要执行的任务 initialDelay – 首次执行的延迟时间 period – 连续执行之间的周期 unit – initialDelay 和 period 参数的时间单位
返回: 代表重复任务系列未完成的 ScheduledFuture。future 的 get() 方法永远不会正常返回,并在任务取消或任务执行异常终止时抛出异常。
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,long initialDelay,long period,TimeUnit unit);
提交一个周期性任务,在给定的 initialDelay 之后首次启用,并在一次执行终止后的给定延迟之后进行下一次执行。 任务执行序列将无限期地继续下去,直到发生以下异常完成之一:
- 通过返回的 future 明确取消任务
- executor 终止,也会导致任务取消
- 任务执行引发异常。在这种情况下,调用返回的 future 的 get 方法将抛出 ExecutionException,保留异常作为其原因。
- 后续执行被抑制。返回的 future 的 isDone() 方法的后续调用将返回 true。
参数:
- command - 要执行的任务
- initialDelay - 首次执行的延迟时间
- delay - 一次执行终止后下一次执行的延迟时间
- unit - initialDelay 和 delay 参数的时间单位
返回:
- 代表重复任务系列未完成的 ScheduledFuture。future 的 get() 方法永远不会正常返回,在任务取消或任务执行异常终止时将抛出异常。
public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command,long initialDelay,long delay, TimeUnit unit);
示例
public class Task implements Runnable {
@Override
public void run() {
System.out.println("Task started");
}
}
public class CallableTask implements Callable<String> {
@Override
public String call() throws Exception {
return "Hello world";
}
}
public class ScheduledExecutorServiceDemo {
private Task runnableTask;
private CallableTask callableTask;
private void execute() {
ScheduledExecutorService executorService = Executors.newSingleThreadScheduledExecutor();
getTasksToRun().apply(executorService);
//executorService.shutdown();
}
private void executeWithMultiThread() {
ScheduledExecutorService executorService = Executors.newScheduledThreadPool(2);
getTasksToRun().apply(executorService);
executorService.shutdown();
}
private Function<ScheduledExecutorService, Void> getTasksToRun() {
runnableTask = new Task();
callableTask = new CallableTask();
return (executorService -> {
Future<String> resultFuture = executorService.schedule(callableTask, 1, TimeUnit.SECONDS);
try {
System.out.println(resultFuture.get().toString());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
//executorService.scheduleAtFixedRate(runnableTask, 1, 5, TimeUnit.SECONDS);
executorService.scheduleWithFixedDelay( runnableTask, 1, 5, TimeUnit.SECONDS);
return null;
});
}
public static void main(String... args) throws InterruptedException {
ScheduledExecutorServiceDemo demo = new ScheduledExecutorServiceDemo();
demo.execute();
//demo.executeWithMultiThread();
Thread.sleep(10000);
}
}
TimeUnit
概述
TimeUnit 是一个表示以给定单位的粒度表示时间持续时间的类,并提供转换单位的实用方法以及在这些单位中执行定时和延迟操作。 TimeUnit 不会维护时间信息,而只会帮助组织和使用可能在各种上下文中单独维护的时间表示。 纳秒被定义为微秒的千分之一,微秒被定义为毫秒的千分之一,毫秒被定义为秒的千分之一,分钟被定义为 60 秒,小时被定义为 60 分钟,天被定义为 24 小时。 TimeUnit 主要用于告知基于时间的方法应该如何解释给定的计时参数。 例如,以下代码将在 50 毫秒内超时,如果锁不可用:
Lock lock = ...;
if (lock.tryLock(50L, TimeUnit.MILLISECONDS)) ...
while this code will timeout in 50 seconds:
Lock lock = ...;
if (lock.tryLock(50L, TimeUnit.SECONDS)) ...
但是请注意,特定的超时实现并不能保证以与给定的 TimeUnit 相同的粒度注意到时间的流逝。
用例
public class TimeUnitTest {
@Test
public void testConvert(){
long seconds =TimeUnit.SECONDS.convert(1,TimeUnit.HOURS);
//1小时转换为秒
Assert.assertEquals(3600,seconds);
//1分钟转为秒
long minutes =TimeUnit.SECONDS.convert(1,TimeUnit.MINUTES);
Assert.assertEquals(60,minutes);
}
@Test
public void testConvertDuration(){
long convert = TimeUnit.MILLISECONDS.convert(Duration.of(1, ChronoUnit.SECONDS));
//1秒转换为毫秒
Assert.assertEquals(1000,convert);
}
@Test
public void testOf(){
//1天转换为小时
long hours = TimeUnit.of(ChronoUnit.DAYS).toHours(1);
Assert.assertEquals(24,hours);
}
@Test
public void testTimeWait() throws InterruptedException {
Object lock = new Object();
synchronized (lock) {
long now = System.nanoTime();
TimeUnit.SECONDS.timedWait(lock, 1);
long nanos = System.nanoTime() - now;
//1010055500 大约为1秒
System.out.println(nanos);
}
}
@Test
public void testTimedJoin() throws InterruptedException {
Thread t = new Thread(()->{
for(;;){
}
});
t.start();
System.out.println("start wait");
//子线程t等待10秒
TimeUnit.SECONDS.timedJoin(t, 10);
System.out.println("end wait");
}
}
RecursiveTask
概述
一个递归的带结果的ForkJoinTask。 例如,这是一个计算斐波那契数列的任务:
class Fibonacci extends RecursiveTask<Integer> {
final int n;
Fibonacci(int n) { this.n = n; }
protected Integer compute() {
if (n <= 1)
return n;
Fibonacci f1 = new Fibonacci(n - 1);
f1.fork();
Fibonacci f2 = new Fibonacci(n - 2);
return f2.compute() + f1.join();
}
}
然而,除了是计算斐波那契数列的愚蠢方法(实际上有一个简单的快速线性算法)外,它很可能表现不佳,因为最小的子任务太小,不值得分裂。相反,就像几乎所有的fork / join应用程序一样,您会选择一个最小的粒度大小(例如这里的10),始终顺序解决而不是细分。
FutureTask
概述
可取消的异步计算。该类提供了 Future 的基本实现,具有启动和取消计算、查询计算是否完成以及检索计算结果的方法。只有在计算完成时才能检索结果;如果计算尚未完成,则 get 方法将阻塞。一旦计算完成,就无法重新启动或取消计算(除非使用 runAndReset 调用计算)。 FutureTask 可用于包装 Callable 或 Runnable 对象。由于 FutureTask 实现了 Runnable,因此可以将 FutureTask 提交给 Executor 执行。 除了作为独立类使用,该类还提供了可能在创建自定义任务类时有用的受保护功能。
源码解析
public boolean cancel(boolean mayInterruptIfRunning) {
//如果状态不是新并且设置状态为打断或取消失败,则取消失败
if (!(state == NEW && STATE.compareAndSet
(this, NEW, mayInterruptIfRunning ? INTERRUPTING : CANCELLED)))
return false;
try { // in case call to interrupt throws exception
if (mayInterruptIfRunning) {
try {
Thread t = runner;
//打断线程
if (t != null)
t.interrupt();
} finally { // final state
//将状态设置为打断
STATE.setRelease(this, INTERRUPTED);
}
}
} finally {
finishCompletion();
}
return true;
}
//删除并发出所有等待线程的信号,调用done()并将callable置空。
private void finishCompletion() {
// assert state > COMPLETING;
for (WaitNode q; (q = waiters) != null;) {
//将q设置为空
if (WAITERS.weakCompareAndSet(this, q, null)) {
for (;;) {
Thread t = q.thread;
if (t != null) {
q.thread = null;
LockSupport.unpark(t);
}
WaitNode next = q.next;
if (next == null)
break;
q.next = null; // unlink to help gc
q = next;
}
break;
}
}
done();
callable = null; // to reduce footprint
}
private int awaitDone(boolean timed, long nanos)
throws InterruptedException {
// The code below is very delicate, to achieve these goals:
// - call nanoTime exactly once for each call to park
// - if nanos <= 0L, return promptly without allocation or nanoTime
// - if nanos == Long.MIN_VALUE, don't underflow
// - if nanos == Long.MAX_VALUE, and nanoTime is non-monotonic
// and we suffer a spurious wakeup, we will do no worse than
// to park-spin for a while
long startTime = 0L; // Special value 0L means not yet parked
WaitNode q = null;
boolean queued = false;
for (;;) {
int s = state;
if (s > COMPLETING) {
if (q != null)
q.thread = null;
return s;
}
else if (s == COMPLETING)
// We may have already promised (via isDone) that we are done
// so never return empty-handed or throw InterruptedException
Thread.yield();
else if (Thread.interrupted()) {
removeWaiter(q);
throw new InterruptedException();
}
else if (q == null) {
if (timed && nanos <= 0L)
return s;
q = new WaitNode();
}
else if (!queued)
queued = WAITERS.weakCompareAndSet(this, q.next = waiters, q);
else if (timed) {
final long parkNanos;
if (startTime == 0L) { // first time
startTime = System.nanoTime();
if (startTime == 0L)
startTime = 1L;
parkNanos = nanos;
} else {
long elapsed = System.nanoTime() - startTime;
if (elapsed >= nanos) {
removeWaiter(q);
return state;
}
parkNanos = nanos - elapsed;
}
// nanoTime may be slow; recheck before parking
if (state < COMPLETING)
LockSupport.parkNanos(this, parkNanos);
}
else
LockSupport.park(this);
}
}
ThreadPoolExecutor
概述
是一种ExecutorService执行器,它使用可能有多个的池化线程之一来执行每个提交的任务,通常使用Executors工厂方法配置。 线程池解决了两个不同的问题:通常在执行大量异步任务时提供更好的性能,因为减少了每个任务调用开销,并提供了一种限制和管理资源(包括线程)的方法,在执行任务集合时消耗。每个ThreadPoolExecutor还维护一些基本统计信息,如完成任务的数量。 要在广泛的上下文中有用,这个类提供了许多可调整的参数和可扩展性钩子。但是,程序员被敦促使用更方便的Executors工厂方法Executors.newCachedThreadPool(无界线程池,自动线程回收),Executors.newFixedThreadPool(固定大小线程池)和Executors.newSingleThreadExecutor(单个后台线程),它们预配置了最常见用例的设置。否则,在手动配置和调整此类时使用以下指南。
- 设置核心和最大池大小。当新任务被提交时,如果线程数小于核心池大小,则会创建新线程来处理请求,即使其他工作线程是空闲的。否则,如果线程数小于最大池大小,只有在队列满时才会创建新线程来处理请求。
- 按需构建。默认情况下,即使核心线程也只有在新任务到达时才初始化和启动,但可以使用prestartCoreThread或prestartAllCoreThreads动态覆盖。如果您使用非空队列构造池,您可能希望预启动线程。
- 创建新线程。使用ThreadFactory创建新线程。如果未指定,则使用Executors.defaultThreadFactory,它创建线程以在同一个ThreadGroup中并具有相同的NORM_PRIORITY优先级和非守护线程状态。通过提供不同的ThreadFactory,您可以更改线程的名称,线程组,优先级,守护线程状态等。如果ThreadFactory在newThread中返回null时无法创建线程,执行器将继续运行,但可能无法执行任何任务。线程应具有"modifyThread"RuntimePermission。如果工作线程或使用池的其他线程没有此权限,服务可能会降级:配置更改可能无法及时生效,关闭池可能仍处于可以终止但未完成的状态。
- 保持活动时间。如果池当前有多于corePoolSize的线程,则如果它们空闲时间超过keepAliveTime(请参阅getKeepAliveTime(TimeUnit)),则会终止过剩线程。这提供了在池未被积极使用时减少资源消耗的方法。如果池后来变得更加活跃,将创建新线程。此参数也可以使用setKeepAliveTime(long,TimeUnit)动态更改。使用Long.MAX_VALUE TimeUnit.NANOSECONDS的值有效地禁用了在关闭之前终止的空闲线程。默认情况下,保持活动策略仅适用于corePoolSize线程以上,但可以使用allowCoreThreadTimeOut(boolean)将此时间限制策略应用于核心线程,只要keepAliveTime值为非零。
- 排队。可以使用任何BlockingQueue来传输和保存提交的任务。使用此队列与池大小进行交互: 如果运行的线程少于corePoolSize,则Executor始终更喜欢添加新线程而不是排队。 如果corePoolSize或更多线程正在运行,则Executor始终更喜欢排队请求而不是添加新线程。 如果请求无法排队,则会创建新线程,除非这会超过maximumPoolSize,在这种情况下,任务将被拒绝。
有三种通用策略排队:
- 直接交接。工作队列的一个很好的默认选择是SynchronousQueue,它将任务交给线程而不进行其他持有。在这里,尝试排队任务将在没有立即可用的线程来运行它时失败,因此将构造新线程。此策略避免在处理具有内部依赖关系的请求集时锁死。直接交接通常需要无限制的maximumPoolSizes来避免拒绝新提交的任务。这反过来允许命令继续到达时线程增长的可能性。
- 固定大小的队列。使用固定大小的队列(例如,ArrayBlockingQueue)将有助于防止资源耗尽,但是可能导致新任务被拒绝。在这种情况下,通过使用ThreadPoolExecutor.CallerRunsPolicy更改拒绝策略,可以使调用者的线程来运行被拒绝的任务。
- 无界队列。使用无界队列(例如,LinkedBlockingQueue)将允许无限制的任务增长,但是可能导致资源耗尽。在大多数生产环境中,更好的做法是使用有界队列并通过调整队列和池大小来预防资源耗尽。
- 拒绝任务。当Executor已经关闭时,在execute(Runnable)方法中提交的新任务将被拒绝,并且当Executor对最大线程和工作队列容量都使用有限边界,且饱和时也会被拒绝。在任何情况下,execute方法都会调用其RejectedExecutionHandler.rejectedExecution(Runnable, ThreadPoolExecutor)方法。提供了四种预定义的处理程序策略:
- 默认的ThreadPoolExecutor.AbortPolicy,在拒绝时,处理程序会抛出运行时RejectedExecutionException。
- ThreadPoolExecutor.CallerRunsPolicy,调用execute的线程本身运行任务。这提供了一种简单的反馈控制机制,可以减缓新任务提交的速度。
- ThreadPoolExecutor.DiscardPolicy,无法执行的任务将简单地被丢弃。此策略仅适用于从不依赖任务完成的罕见情况。
-
ThreadPoolExecutor.DiscardOldestPolicy,如果executor没有关闭,则工作队列头部的任务将被丢弃,然后重试执行(这可能会再次失败,导致重复)。这种策略很少被接受。在几乎所有情况下,您应该取消任务,以在等待完成的任何组件中引起异常,并/或记录失败,如ThreadPoolExecutor.DiscardOldestPolicy文档中所示。
也可以定义和使用其他类型的RejectedExecutionHandler类。这需要特别小心,特别是在策略设计只适用于特定容量或排队策略的情况下。
- 钩子方法:这个类提供了受保护的可重写的beforeExecute(Thread, Runnable)和afterExecute(Runnable, Throwable)方法,在每个任务执行前后调用。它们可用于操作执行环境;例如,重新初始化ThreadLocals,收集统计信息或添加日志条目。此外,可以重写方法terminated以在Executor完全终止后执行任何特殊处理。 如果钩子,回调或BlockingQueue方法抛出异常,内部工作线程可能会失败,突然终止,并可能被替换。
- 队列维护:getQueue()方法允许访问工作队列以进行监视和调试。强烈反对使用此方法进行其他目的。提供的两种方法remove(Runnable)和purge可用于帮助在取消大量排队任务时进行存储回收。
- 回收:在程序中不再引用且没有剩余线程的池可能会被回收(垃圾回收),而无需显式关闭。您可以配置池以允许所有未使用的线程最终死亡,通过设置适当的保活时间,使用零基本线程数和/或设置allowCoreThreadTimeOut(boolean)。
源码解析
主池控制状态 ctl 是一个原子整数,它打包了两个概念字段 workerCount,表示有效线程数 runState,表示运行状态,关闭等为了将它们打包到一个 int 中,我们将 workerCount 限制为 (2^29)-1 (约 5 亿) 线程,而不是 (2^31)-1 (20 亿)。如果将来有问题,变量可以更改为 AtomicLong,并下面调整 shift/mask 常量。但是,在需要时之前,使用 int 的代码更快,更简单。workerCount 是已允许启动并且不允许停止的工作线程数。该值可能与实际存活线程数暂时不同,例如当线程工厂未能在请求时创建线程时,以及在退出线程在终止之前仍在进行账目记录时。用户可见的池大小被报告为 workers 集合的当前大小。runState 提供了主要的生命周期控制,具有以下值:
- RUNNING: 接受新任务并处理排队的任务
- SHUTDOWN: 不接受新任务,但处理排队的任务
- STOP: 不接受新任务,不处理排队的任务,并中断正在进行的任务
- TIDYING: 所有任务已终止,workerCount 为零,正在转换为状态 TIDYING 的线程将运行 terminated() 钩子方法
- TERMINATED: terminated() 已完成
这些值之间的数字顺序很重要,允许有序比较。runState 随时间单调增长,但不需要达到每个状态。转换为:
- RUNNING -> SHUTDOWN 在调用shutdown()时
- (RUNNING or SHUTDOWN) -> STOP 在调用shutdownNow()时
- SHUTDOWN -> TIDYING 队列和池都为空时
- STOP -> TIDYING 池为空时
- TIDYING -> TERMINATED 当 terminated() 钩子方法完成时
在 awaitTermination() 中等待的线程将在状态达到 TERMINATED 时返回。检测 SHUTDOWN 到 TIDYING 的转换不如你想象的那么简单,因为在 SHUTDOWN 状态下队列可能在非空后变为空,反之亦然,但我们只能在看到它是空的后,看到 workerCount 是 0 时终止(这有时需要重新检查 -- 请参见下面)
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static int ctlOf(int rs, int wc) { return rs | wc; }
这是一个用于保存任务和分配给工作线程的队列。我们不要求 workQueue.poll() 返回 null 一定意味着 workQueue.isEmpty(),因此仅依靠 isEmpty 来查看队列是否为空(例如,当决定是否从 SHUTDOWN 转换到 TIDYING 时,我们必须这样做)。这适用于特殊目的队列,例如 DelayQueues,其中 poll() 允许返回 null,即使在延迟过期后可能会返回非空值。
private final BlockingQueue<Runnable> workQueue;
拒绝处理程序,当 execute 中线程池饱和或关闭时,会调用此处理程序。
private volatile RejectedExecutionHandler handler;
在调用shutdown和shutdownNow时需要权限。 我们还需要(参见checkShutdownAccess)调用者有权实际中断工作线程集中的线程(由Thread.interrupt管理,它依赖于ThreadGroup.checkAccess,又依赖于SecurityManager.checkAccess)。 只有在通过这些检查之后,才尝试关闭。 Thread.interrupt的所有实际调用(参见interruptIdleWorkers和interruptWorkers)忽略SecurityExceptions,这意味着尝试中断将静默失败。 在关闭的情况下,除非SecurityManager具有不一致的策略,有时允许访问线程,有时不允许,否则它们不应该失败。 在这种情况下,无法实际中断线程可能会禁用或延迟完全终止。 使用interruptIdleWorkers的其他用途是建议性的,并且无法实际中断将仅延迟对配置更改的响
private static final RuntimePermission shutdownPerm =new RuntimePermission("modifyThread");
这个类 Worker 主要维护线程运行任务时的中断控制状态,以及其他的小的记录。这个类机会性地扩展了 AbstractQueuedSynchronizer ,以简化在每个任务执行时获取和释放锁。这可以保护那些企图唤醒等待任务的工作线程而不是中断正在运行的任务的中断。我们实现了一个简单的不可重入互斥锁,而不是使用 ReentrantLock ,因为我们不希望工作任务在调用 setCorePoolSize 等池控制方法时能够重新获取锁。此外,为了在线程实际开始运行任务之前阻止中断,我们将锁定状态初始化为负值,并在启动时清除它(在 runWorker 中)。
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
{
/**
* This class will never be serialized, but we provide a
* serialVersionUID to suppress a javac warning.
*/
private static final long serialVersionUID = 6138294804551838833L;
/** Thread this worker is running in. Null if factory fails. */
@SuppressWarnings("serial") // Unlikely to be serializable
final Thread thread;
/** Initial task to run. Possibly null. */
@SuppressWarnings("serial") // Not statically typed as Serializable
Runnable firstTask;
/** Per-thread task counter */
volatile long completedTasks;
// TODO: switch to AbstractQueuedLongSynchronizer and move
// completedTasks into the lock word.
/**
* Creates with given first task and thread from ThreadFactory.
* @param firstTask the first task (null if none)
*/
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
/** Delegates main run loop to outer runWorker. */
public void run() {
runWorker(this);
}
// Lock methods
//
// The value 0 represents the unlocked state.
// The value 1 represents the locked state.
protected boolean isHeldExclusively() {
return getState() != 0;
}
protected boolean tryAcquire(int unused) {
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
protected boolean tryRelease(int unused) {
setExclusiveOwnerThread(null);
setState(0);
return true;
}
public void lock() { acquire(1); }
public boolean tryLock() { return tryAcquire(1); }
public void unlock() { release(1); }
public boolean isLocked() { return isHeldExclusively(); }
void interruptIfStarted() {
Thread t;
if (getState() >= 0 && (t = thread) != null && !t.isInterrupted()) {
try {
t.interrupt();
} catch (SecurityException ignore) {
}
}
}
}
//将运行状态转换到给定目标,如果已经至少是给定目标,则保持不变。
参数:
targetState - 所需状态,SHUTDOWN或STOP (但不是TIDYING或TERMINATED - 使用tryTerminate)
private void advanceRunState(int targetState) {
// assert targetState == SHUTDOWN || targetState == STOP;
for (;;) {
int c = ctl.get();
if (runStateAtLeast(c, targetState) ||
ctl.compareAndSet(c, ctlOf(targetState, workerCountOf(c))))
break;
}
}
这个方法将状态转换为 TERMINATED,如果符合以下条件之一:(SHUTDOWN 并且线程池和队列为空) 或者 (STOP 并且线程池为空)。如果本来就有资格终止,但 workerCount 不为 0,则中断一个空闲的工作线程,以确保关闭信号传播。这个方法必须在任何可能导致终止的操作之后调用 - 在关闭期间减少工作线程数或从队列中删除任务。这个方法是非私有的,允许从 ScheduledThreadPoolExecutor 访问。
final void tryTerminate() {
for (;;) {
int c = ctl.get();
//如果再运行中或runState 是否至少为 TIDYING 状态,或状态小于停止且工作队列为空
if (isRunning(c) ||
runStateAtLeast(c, TIDYING) ||
(runStateLessThan(c, STOP) && ! workQueue.isEmpty()))
return;
//工作数量不等于0
if (workerCountOf(c) != 0) { // Eligible to terminate
interruptIdleWorkers(ONLY_ONE);
return;
}
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
if (ctl.compareAndSet(c, ctlOf(TIDYING, 0))) {
try {
/调用模板方法,由子类具体实现
terminated();
} finally {
ctl.set(ctlOf(TERMINATED, 0));
termination.signalAll();
}
return;
}
} finally {
mainLock.unlock();
}
// else retry on failed CAS
}
}
如果有安全管理器,确保调用者有权限在一般情况下关闭线程(参见shutdownPerm)。如果通过了这个检查,还需要确保调用者被允许中断每个工作线程。即使第一个检查通过了,如果SecurityManager对某些线程有特殊处理,这可能是不成立的。
private void checkShutdownAccess() {
// assert mainLock.isHeldByCurrentThread();
@SuppressWarnings("removal")
SecurityManager security = System.getSecurityManager();
if (security != null) {
security.checkPermission(shutdownPerm);
for (Worker w : workers)
security.checkAccess(w.thread);
}
}
把任务队列中的任务排空到一个新的列表中,通常使用drainTo。但如果队列是DelayQueue或其他类型的队列,poll或drainTo可能会删除一些元素失败,它会一个一个地删除它们。
private List<Runnable> drainQueue() {
BlockingQueue<Runnable> q = workQueue;
ArrayList<Runnable> taskList = new ArrayList<>();
q.drainTo(taskList);
if (!q.isEmpty()) {
for (Runnable r : q.toArray(new Runnable[0])) {
if (q.remove(r))
taskList.add(r);
}
}
return taskList;
}
检查是否可以根据当前池状态和给定边界(核心或最大值)添加新工作线程。如果可以,则相应地调整工作线程计数,并在可能的情况下创建并启动新工作线程,将 firstTask 运行为其第一个任务。如果池已停止或有资格关闭,则此方法返回 false。如果线程工厂无法创建线程,也会返回 false。如果线程创建失败,要么是因为线程工厂返回 null,要么是因为异常(通常是 Thread.start() 中的 OutOfMemoryError),我们将清理回滚。
参数:
firstTask - 新线程应运行的第一个任务(如果没有则为 null)。通过在执行方法中使用初始 firstTask 创建工作线程,可以在线程数小于 corePoolSize 时(在这种情况下我们始终启动一个)或队列已满时(此时我们必须绕过队列)绕过排队。最初空闲线程通常是通过 prestartCore
private boolean addWorker(Runnable firstTask, boolean core) {
retry: //goto 语句,避免死循环
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
/*如果线程处于非运行状态,并且 rs 不等于 SHUTDOWN 且 firstTask 不等于空且且
workQueue 为空,直接返回 false(表示不可添加 work 状态)
1. 线程池已经 shutdown 后,还要添加新的任务,拒绝
2. (第二个判断)SHUTDOWN 状态不接受新任务,但仍然会执行已经加入任务队列的任
务,所以当进入 SHUTDOWN 状态,而传进来的任务为空,并且任务队列不为空的时候,是允许添加
新线程的,如果把这个条件取反,就表示不允许添加 worker*/
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) { //自旋
int wc = workerCountOf(c);//获得 Worker 工作线程数
//如果工作线程数大于默认容量大小或者大于核心线程数大小,则直接返回 false 表示不
能再添加 worker。
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
if (compareAndIncrementWorkerCount(c))//通过 cas 来增加工作线程数,如果 cas 失败,则直接重试
break retry;
c = ctl.get(); // Re-read ctl //再次获取 ctl 的值
if (runStateOf(c) != rs) //这里如果不想等,说明线程的状态发生了变化,继续重试
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
//上面这段代码主要是对 worker 数量做原子+1 操作,下面的逻辑才是正式构建一个 worker
boolean workerStarted = false; //工作线程是否启动的标识
boolean workerAdded = false; //工作线程是否已经添加成功的标识
Worker w = null;
try {
w = new Worker(firstTask); //构建一个 Worker,这个 worker 是什么呢?我们可以看到构造方法里面传入了一个 Runnable 对象
final Thread t = w.thread; //从 worker 对象中取出线程
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock(); //这里有个重入锁,避免并发问题
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int rs = runStateOf(ctl.get());
//只有当前线程池是正在运行状态,[或是 SHUTDOWN 且 firstTask 为空],才能添加到 workers 集合中
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
//任务刚封装到 work 里面,还没 start,你封装的线程就是 alive,几个意思?肯定是要抛异常出去的
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
workers.add(w); //将新创建的 Worker 添加到 workers 集合中
int s = workers.size();
//如果集合中的工作线程数大于最大线程数,这个最大线程数表示线程池曾经出现过的最大线程数
if (s > largestPoolSize)
largestPoolSize = s; //更新线程池出现过的最大线程数
workerAdded = true;//表示工作线程创建成功了
}
} finally {
mainLock.unlock(); //释放锁
}
if (workerAdded) {//如果 worker 添加成功
t.start();//启动线程
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w); //如果添加失败,就需要做一件事,就是递减实际工作线程数(还记得我们最开始的时候增加了工作线程数吗)
}
return workerStarted;//返回结果
}
这个方法用于线程池中处理即将退出的工作线程的清理和记录工作。除非 completedAbruptly 设置为 true,否则假设 workerCount 已经调整以账户退出。该方法从工作线程集中删除线程,并可能终止池或替换工作线程,如果它由于用户任务异常退出或运行的工作线程少于 corePoolSize,或队列非空但没有工作线程。
参数:
w-工作线程
completedAbruptly-如果工作线程因用户异常死亡。
这个方法处理工作线程退出时的清理和记录工作。首先,如果completedAbruptly被设置为true,则表示工作线程因为用户异常退出,那么会调用decrementWorkerCount()减少工作线程计数。接着,使用ReentrantLock对象mainLock锁定,并将工作线程从workers集合中移除,并增加完成的任务数。
然后调用tryTerminate()尝试终止线程池。如果线程池的运行状态小于STOP,则尝试添加新的工作线程。如果completedAbruptly为false,则只有当运行的工作线程数量小于corePoolSize或者工作队列不为空时才会添加新的工作线程。
private void processWorkerExit(Worker w, boolean completedAbruptly) {
if (completedAbruptly) // If abrupt, then workerCount wasn't adjusted
decrementWorkerCount();
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
completedTaskCount += w.completedTasks;
workers.remove(w);
} finally {
mainLock.unlock();
}
tryTerminate();
int c = ctl.get();
//线程池的运行状态小于STOP
if (runStateLessThan(c, STOP)) {
if (!completedAbruptly) {
int min = allowCoreThreadTimeOut ? 0 : corePoolSize;
if (min == 0 && ! workQueue.isEmpty())
min = 1;
if (workerCountOf(c) >= min)
return; // replacement not needed
}
addWorker(null, false);
}
}
这是工作线程的主要运行循环。它会重复地从队列中获取任务并执行它们,同时处理一些问题:
1.我们可能会先执行初始任务,在这种情况下我们不需要获取第一个任务。否则,只要线程池正在运行,我们就会从getTask中获取任务。如果返回null,则工作线程会由于线程池状态或配置参数的更改而退出。其他退出是由于外部代码中的异常抛出导致的,在这种情况下completedAbruptly为true,通常会导致processWorkerExit替换此线程。
2.在运行任何任务之前,将获取锁以防止在任务执行期间其他线程池中断,然后确保除非线程池停止,否则此线程不会设置其中断。
3.在运行任务之前,会调用beforeExecute,这可能会导致异常,在这种情况下我们会导致线程死亡(使用completedAbruptly true终止循环)而不处理任务。
4.假设beforeExecute正常完成,我们会运行任务,并收集其抛出的任何异常以发送给afterExecute。我们分别处理RuntimeException,Error(规范保证我们处理这两种情况)和任意Throwables。因为我们无法在Runnable.run中重新抛出Throwables,我们在退出时将它们包装在Errors中(传递到线程的UncaughtExceptionHandler)。任何抛出的异常也会保守地导致线程死亡。
5.在任务.run完成后,我们调用afterExecute,它也可能会抛出异常,这也会导致线程死亡。根据JLS Sec 14.20,即使任务.run抛出异常,此异常也将生效。异常机制的净效果是afterExecute和线程的UncaughtExceptionHandler都拥有我们能提供的关于用户代码遇到的任何问题的准确信息。
这个方法运行工作线程w。首先,获取当前线程wt,并获取w的第一个任务。然后设置w的第一个任务为null,并解锁w以允许中断。completedAbruptly设置为true,表示工作线程因为异常而退出。之后,使用while循环获取任务并执行。在循环开始之前锁定w,确保线程池正在运行或线程未被中断。然后调用beforeExecute,执行任务,如果发生异常调用afterExecute并抛出异常。循环结束后,completedAbruptly设置为false,调用processWorkerExit处理工作线程退出。
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {
w.lock();
// If pool is stopping, ensure thread is interrupted;
// if not, ensure thread is not interrupted. This
// requires a recheck in second case to deal with
// shutdownNow race while clearing interrupt
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);
try {
task.run();
afterExecute(task, null);
} catch (Throwable ex) {
afterExecute(task, ex);
throw ex;
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
这个方法用于执行给定的任务command。首先检查command是否为空,如果为空则抛出空指针异常。
接下来,方法执行三个步骤:
1.如果运行的工作线程数量小于corePoolSize,则尝试使用给定的命令作为其第一个任务启动新线程。调用addWorker会原子地检查runState和workerCount,从而防止在不应该添加线程时添加线程,返回false。
2.如果成功地排队了任务,则仍需要再次检查是否应该添加线程(因为自上次检查以来存在的线程已死亡)或线程池自入口处关闭。因此,我们重新检查状态,如果需要,则回滚入队(如果停止)或启动新线程(如果没有线程)。
3.如果无法排队任务,则尝试添加新线程。如果失败,则知道已关闭或饱和,因此拒绝任务。
总之,这个方法会检查当前线程池的状态,如果线程数量小于corePoolSize,则尝试添加新的工作线程来执行给定的任务。如果线程池正在运行并且任务队列未满,则将任务加入队列。如果无法将任务加入队列,则尝试添加新的工作线程,如果无法添加新的工作线程,则拒绝执行该任
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
*/
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}
RunnableScheduledFuture
概述
ScheduledFuture是一种Runnable。run方法的成功执行会导致Future完成,并允许访问其结果。
源码解析
如果这个任务是周期性的,返回true。周期性任务可能根据某种时间表重新运行。非周期性任务只能运行一次。 返回值: 如果这个任务是周期性的,返回true。
boolean isPeriodic();
ExecutorService
概述
ExecutorService是一种Executor,它提供了管理终止和生成用于跟踪一个或多个异步任务进度的Future的方法。 ExecutorService可以关闭,这会导致它拒绝新任务。提供了两种不同的关闭ExecutorService的方法。shutdown方法将允许以前提交的任务在终止之前执行,而shutdownNow方法阻止等待任务启动并尝试停止当前执行的任务。在终止时,执行器没有积极执行的任务,没有等待执行的任务,也不能提交新任务。未使用的ExecutorService应该关闭以允许释放其资源。 submit方法通过创建并返回一个Future来扩展基本方法Executor.execute(Runnable)。该Future可用于取消执行和/或等待完成。invokeAny和invokeAll方法执行最常用的批量执行形式,执行一组任务然后等待至少一个或全部完成。(可以使用ExecutorCompletionService类编写这些方法的定制变体。
源码解析
void shutdown(); 启动有序关闭,先前提交的任务将被执行,但不会接受新任务。如果已经关闭,调用没有额外的效果。 此方法不等待先前提交的任务完成执行。使用awaitTermination来实现。
List<Runnable> shutdownNow(); 尝试停止所有正在执行的任务,中止等待任务的处理,并返回正在等待执行的任务列表。 此方法不等待正在执行的任务终止。使用awaitTermination来实现。 除了尽最大努力停止处理正在执行的任务之外,没有任何保证。例如,典型的实现将通过Thread.interrupt取消,因此任何未响应中断的任务可能永远不会终止。
boolean isShutdown();如果这个执行器已经关闭,返回true。
boolean isTerminated(); 如果在关闭后所有任务都已完成,则返回true。请注意,除非调用了shutdown或shutdownNow,isTerminated永远不会是true。
boolean awaitTermination(long timeout, TimeUnit unit)在关闭请求后阻塞,直到所有任务完成执行,或超时发生,或当前线程被中断,取决于哪个先发生。
<T> Future<T> submit(Callable<T> task);提交一个返回值任务执行并返回一个代表任务待处理结果的Future。在成功完成任务后,Future的get方法将返回任务的结果。 如果您希望立即阻塞等待任务,可以使用类似于 result = exec.submit(aCallable).get()的结构。 注意: Executors类包括一组可以将其他一些常见的闭包类对象(例如java.security.PrivilegedAction)转换为Callable形式的方法,以便它们可以提交。
<T> Future<T> submit(Runnable task, T result);提交一个可运行的任务执行并返回一个代表该任务的Future。在成功完成后,Future的get方法将返回给定的结果。
Future<?> submit(Runnable task);提交一个可运行的任务执行并返回一个代表该任务的Future。在成功完成后,Future的get方法将返回null。
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks)执行给定的任务,在所有完成时返回一个保存其状态和结果的Future列表。当返回列表的每个元素完成时,Future.isDone为true。请注意,完成的任务可能正常终止或抛出异常。如果在此操作进行时修改了给定的集合,则此方法的结果是未定义的。
<T> T invokeAny(Collection<? extends Callable<T>> tasks)执行给定的任务,如果有成功完成(即没有抛出异常)的任务,则返回其结果。在正常或异常返回时,取消尚未完成的任务。如果在此操作进行时修改了给定的集合,则此方法的结果是未定义的。
用例
public class Java8ExecutorServiceIntegrationTest {
private Runnable runnableTask;
private Callable<String> callableTask;
private List<Callable<String>> callableTasks;
@Before
public void init() {
runnableTask = () -> {
try {
TimeUnit.MILLISECONDS.sleep(300);
} catch (InterruptedException e) {
e.printStackTrace();
}
};
callableTask = () -> {
TimeUnit.MILLISECONDS.sleep(300);
return "Task's execution";
};
callableTasks = new ArrayList<>();
callableTasks.add(callableTask);
callableTasks.add(callableTask);
callableTasks.add(callableTask);
}
@Test
public void creationSubmittingTaskShuttingDown_whenShutDown_thenCorrect() {
ExecutorService executorService = Executors.newFixedThreadPool(10);
executorService.submit(runnableTask);
executorService.submit(callableTask);
executorService.shutdown();
assertTrue(executorService.isShutdown());
}
@Test
public void creationSubmittingTasksShuttingDownNow_whenShutDownAfterAwating_thenCorrect() {
ExecutorService threadPoolExecutor = new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<>());
for (int i = 0; i < 100; i++) {
threadPoolExecutor.submit(callableTask);
}
List<Runnable> notExecutedTasks = smartShutdown(threadPoolExecutor);
assertTrue(threadPoolExecutor.isShutdown());
assertFalse(notExecutedTasks.isEmpty());
assertTrue(notExecutedTasks.size() < 98);
}
private List<Runnable> smartShutdown(ExecutorService executorService) {
List<Runnable> notExecutedTasks = new ArrayList<>();
executorService.shutdown();
try {
if (!executorService.awaitTermination(800, TimeUnit.MILLISECONDS)) {
notExecutedTasks = executorService.shutdownNow();
}
} catch (InterruptedException e) {
notExecutedTasks = executorService.shutdownNow();
}
return notExecutedTasks;
}
@Test
public void submittingTasks_whenExecutedOneAndAll_thenCorrect() {
ExecutorService executorService = Executors.newFixedThreadPool(10);
String result = null;
List<Future<String>> futures = new ArrayList<>();
try {
result = executorService.invokeAny(callableTasks);
futures = executorService.invokeAll(callableTasks);
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
assertEquals("Task's execution", result);
assertTrue(futures.size() == 3);
}
@Test
public void submittingTaskShuttingDown_whenGetExpectedResult_thenCorrect() {
ExecutorService executorService = Executors.newFixedThreadPool(10);
Future<String> future = executorService.submit(callableTask);
String result = null;
try {
result = future.get();
result = future.get(200, TimeUnit.MILLISECONDS);
} catch (InterruptedException | ExecutionException | TimeoutException e) {
e.printStackTrace();
}
executorService.shutdown();
assertEquals("Task's execution", result);
}
@Test
public void submittingTask_whenCanceled_thenCorrect() {
ExecutorService executorService = Executors.newFixedThreadPool(10);
Future<String> future = executorService.submit(callableTask);
boolean canceled = future.cancel(true);
boolean isCancelled = future.isCancelled();
executorService.shutdown();
assertTrue(canceled);
assertTrue(isCancelled);
}
@Test
public void submittingTaskScheduling_whenExecuted_thenCorrect() {
ScheduledExecutorService executorService = Executors.newSingleThreadScheduledExecutor();
Future<String> resultFuture = executorService.schedule(callableTask, 1, TimeUnit.SECONDS);
String result = null;
try {
result = resultFuture.get();
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
executorService.shutdown();
assertEquals("Task's execution", result);
}
}
TimeoutException
概述
当阻塞操作超时时抛出异常。指定超时的阻塞操作需要一种表示超时已发生的方法。对于许多这样的操作,可以返回表示超时的值;当这不可能或不可取时,应该声明并抛出 TimeoutException。
CopyOnWriteArraySet
概述
CopyOnWriteArraySet是一种使用内部CopyOnWriteArrayList进行所有操作的集合。因此,它具有相同的基本属性: 它最适合于集合大小通常保持较小、只读操作远多于可变操作、并且需要在遍历期间防止线程之间干扰的应用程序。 它是线程安全的。 可变操作(添加、设置、删除等)很昂贵,因为它们通常需要复制整个基础数组。 迭代器不支持可变删除操作。 通过迭代器进行遍历是快速的,不会遇到其他线程的干扰。迭代器依赖于在构造迭代器时数组的不变快照。
原理分析
Executor
概述
行每个任务的机制分离开来的方法,包括线程使用、调度等的细节。通常使用Executor而不是明确创建线程。例如,与其为一组任务中的每个任务调用new Thread(new RunnableTask()).start(),您可能会使用:
Executor executor = anExecutor();
executor.execute(new RunnableTask1());
executor.execute(new RunnableTask2());
尽管如此,Executor接口并不严格要求执行是异步的。在最简单的情况下,执行器可以立即在调用者的线程中运行提交的任务:
class DirectExecutor implements Executor {
public void execute(Runnable r) {
r.run();
}
}
通常来说,任务在调用者的线程之外的某些线程中执行。下面的执行器为每个任务生成一个新线程。
class ThreadPerTaskExecutor implements Executor {
public void execute(Runnable r) {
new Thread(r).start();
}
}
许多Executor实现对任务的调度方式和时间施加某种限制。下面的执行器将任务的提交串行化到第二个执行器,揭示了一个复合执行器。
class SerialExecutor implements Executor {
final Queue<Runnable> tasks = new ArrayDeque<>();
final Executor executor;
Runnable active;
SerialExecutor(Executor executor) {
this.executor = executor;
}
public synchronized void execute(Runnable r) {
tasks.add(() -> {
try {
r.run();
} finally {
scheduleNext();
}
});
if (active == null) {
scheduleNext();
}
}
protected synchronized void scheduleNext() {
if ((active = tasks.poll()) != null) {
executor.execute(active);
}
}
}
Executor实现在这个包中提供了ExecutorService,这是一个更广泛的接口。ThreadPoolExecutor类提供了一个可扩展的线程池实现。 Executors类提供了这些Executors的方便工厂方法。 内存一致性效果:在将Runnable对象提交给Executor之前在线程中的操作对于它在另一个线程中开始执行具有happen-before关系。
源码解析
execute() 在将来的某个时刻执行给定的命令。命令可能在新线程、池线程或调用线程中执行,由Executor实现决定。
Phaser
概述
Phaser是一个可重用的同步屏障,功能类似于CyclicBarrier和CountDownLatch,但支持更灵活的使用方式。 注册。与其他屏障不同,注册到Phaser上进行同步的参与方数量可以随时间变化。任务可以随时注册(使用register方法、bulkRegister方法或用于建立初始参与方数量的构造函数形式),并在任何到达时选择性地取消注册(使用arriveAndDeregister方法)。与大多数基本同步构造不同,注册和取消注册仅影响内部计数;它们不建立任何进一步的内部簿记,因此任务无法查询它们是否已注册。(但是,您可以通过子类化此类来引入此类簿记。) 同步。与CyclicBarrier类似,Phaser可以重复等待。方法arriveAndAwaitAdvance的效果类似于CyclicBarrier.await。每个Phaser的一代都有一个关联的阶段编号。阶段编号从零开始,在所有参与方到达Phaser时前进,达到Integer.MAX_VALUE后绕回零。使用阶段编号可以通过两种类型的方法独立控制到达Phaser时和等待其他方时的操作,这些方法可以由任何已注册的参与方调用:
- 到达。arrive和arriveAndDeregister方法记录到达。这些方法不会阻塞,而是返回关联的到达阶段号;即,到达应用的Phaser的阶段号。当给定阶段的最后一个参与方到达时,将执行可选操作并推进阶段。这些操作由触发阶段推进的参与方执行,并且通过覆盖方法onAdvance(int, int)进行安排,该方法还控制终止。覆盖此方法类似于但比为CyclicBarrier提供屏障动作更灵活。
- 等待。awaitAdvance方法需要指示到达阶段号的参数,并在Phaser推进到(或已经在)不同阶段时返回。与使用CyclicBarrier的类似构造不同,即使等待线程被中断,awaitAdvance方法仍然继续等待。还提供了可中断和超时版本,但是在任务可中断等待或超时等待时遇到的异常不会改变Phaser的状态。如果需要,在这些异常的处理程序中可以执行任何关联的恢复操作,通常在调用forceTermination后执行。Phasers也可以被ForkJoinPool中执行的任务使用。如果池的并行级别可以容纳同时阻塞的最大参与方数量,则可以确保进度。
终止。Phaser可以进入终止状态,可以使用isTerminated方法进行检查。在终止时,所有同步方法将立即返回,而不必等待推进,这由负返回值指示。类似地,尝试在终止时注册不会产生任何效果。当onAdvance方法的调用返回true时,将触发终止。默认实现在取消注册导致注册方数量变为零时返回true。如下所示,当Phaser控制具有固定迭代次数的操作时,通常方便重写此方法以在当前阶段号达到阈值时导致终止。还提供了forceTermination方法,用于突然释放等待线程并允许它们终止。
分层。Phaser可以分层(即构建为树结构)以减少争用。具有大量参与方的Phaser,否则可能会经历大量同步争用成本,可以设置为子Phaser的组共享一个公共父Phaser。即使产生更大的每次操作开销,这也可能会大大增加吞吐量。 在分层Phaser树中,子Phaser与其父Phaser的注册和注销是自动管理的。每当子Phaser的注册方数量变为非零(如在Phaser(Phaser, int)构造函数,register或bulkRegister中确定的),子Phaser将与其父Phaser注册。每当由于调用arriveAndDeregister而导致注册方数量变为零时,子Phaser将从其父Phaser中注销。
监控。虽然同步方法只能由已注册方调用,但任何调用者都可以监视Phaser的当前状态。在任何给定时刻,总共有getRegisteredParties个参与方,其中getArrivedParties个已经到达当前阶段(getPhase)。当剩余的(getUnarrivedParties)参与方到达时,阶段将推进。这些方法返回的值可能反映了瞬时状态,因此通常不适用于同步控制。toString方法以便于非正式监视的形式返回这些状态查询的快照。
内存一致性影响:在任何形式的到达方法之前的操作都会发生在相应的阶段推进和onAdvance操作之前(如果存在),然后发生在阶段推进之后的操作。
样例用法: Phaser可以用来控制一次性动作,为可变数量的参与方提供服务,而不是使用CountDownLatch。典型的惯用法是首先注册设置这一点的方法,然后启动所有操作,然后注销,如下所示:
void runTasks(List<Runnable> tasks) {
Phaser startingGate = new Phaser(1); // "1" to register self
// create and start threads
for (Runnable task : tasks) {
startingGate.register();
new Thread(() -> {
startingGate.arriveAndAwaitAdvance();
task.run();
}).start();
}
// deregister self to allow threads to proceed
startingGate.arriveAndDeregister();
}
导致一组线程重复执行一定数量的迭代操作的一种方法是重写onAdvance方法:
void startTasks(List<Runnable> tasks, int iterations) {
Phaser phaser = new Phaser() {
protected boolean onAdvance(int phase, int registeredParties) {
return phase >= iterations - 1 || registeredParties == 0;
}
};
phaser.register();
for (Runnable task : tasks) {
phaser.register();
new Thread(() -> {
do {
task.run();
phaser.arriveAndAwaitAdvance();
} while (!phaser.isTerminated());
}).start();
} // allow threads to proceed; don't wait for them phaser.arriveAndDeregister();
}
如果主任务后续必须等待终止,它可以重新注册,然后执行类似的循环:
phaser.register();
while (!phaser.isTerminated())
phaser.arriveAndAwaitAdvance();
在您确定阶段永远不会环绕Integer.MAX_VALUE的情况下,可以使用相关构造来等待特定阶段号,例如:
void awaitPhase(Phaser phaser, int phase) {
int p = phaser.register(); // assumes caller not already registered
while (p < phase) {
if (phaser.isTerminated()) {
// ... deal with unexpected termination
}else
p = phaser.arriveAndAwaitAdvance();
}
phaser.arriveAndDeregister();
}
要使用Phaser的树形结构创建一组n个任务,可以使用以下形式的代码,假设有一个接受Phaser并在构造时注册的Task类构造函数。在调用build(new Task[n], 0, n, new Phaser())之后,这些任务可以被启动,例如通过提交给线程池:
void build(Task[] tasks, int lo, int hi, Phaser ph) {
if (hi - lo > TASKS_PER_PHASER) {
for (int i = lo; i < hi; i += TASKS_PER_PHASER) {
int j = Math.min(i + TASKS_PER_PHASER, hi);
build(tasks, i, j, new Phaser(ph));
}
} else {
for (int i = lo; i < hi; ++i)
tasks[i] = new Task(ph);
// assumes new Task(ph) performs ph.register()
}
}
TASKS_PER_PHASER的最佳值主要取决于预期的同步率。对于极小的每阶段任务体(因此具有较高的速率),可能适合使用低至四的值,或者对于极大的任务体,可能达到数百。 实现注意事项:此实现将最大参与方数限制为65535。尝试注册额外的参与方将导致IllegalStateException。但是,您可以并且应该创建分层的Phaser以容纳任意大的参与者集合。
ForkJoinTask
概述
ForkJoinTask是一个在ForkJoinPool中运行的任务的抽象基类。ForkJoinTask是一种类似线程的实体,比普通线程轻得多。在ForkJoinPool中,大量的任务和子任务可以由少量的实际线程托管,以牺牲一些使用限制为代价。
一个"主"ForkJoinTask在显式提交到ForkJoinPool时开始执行,或者如果还没有参与ForkJoin计算,则通过fork、invoke或相关方法在ForkJoinPool.commonPool()中启动。一旦开始,它通常会继续开始其他子任务。如该类名称所示,许多使用ForkJoinTask的程序仅使用fork和join或其衍生方法(例如invokeAll)。然而,这个类也提供了许多其他方法,在高级用法中可能会涉及,以及扩展机制,支持新形式的分治/合并处理。
ForkJoinTask是Future的轻量级形式。ForkJoinTask的效率源于一组限制(只是部分静态可强制执行的),反映了它们作为计算纯函数或在纯独立对象上操作的计算任务的主要用途。主要的协调机制是fork,安排异步执行,和join,在任务的结果计算完成之前不会继续。计算理论上应该避免使用同步方法或块,并应尽量减少其他阻塞同步,除了加入其他任务或使用诸如Phaser之类的同步器,它们被宣布与分治/合并调度合作。可分割的任务也不应执行阻塞I/O,并且理想情况下应访问与其他运行任务完全独立的变量。这些指导方针通过不允许抛出诸如IOException之类的受检异常而得到松散执行。然而,计算仍然可能遇到未经检查的异常,这些异常会重新抛回试图加入它们的调用者。这些异常还可能包括来自内部资源耗尽的RejectedExecutionException,例如分配内部任务队列失败。重新抛出的异常的行为与常规异常相同,但是,如果可能,它们包含堆栈跟踪(例如使用ex.printStackTrace()显示)
可以定义和使用可能阻塞的 ForkJoinTasks,但这需要考虑三个方面:(1) 对于阻塞于外部同步或 I/O 的任务,很少有其他任务的完成依赖于它。从不进行联合的事件风格异步任务(例如,那些子类化 CountedCompleter)通常属于这一类。(2) 为了最大限度地减小资源影响,任务应该小巧;理想情况下仅执行(可能)阻塞操作。(3) 除非使用 ForkJoinPool.ManagedBlocker API,或者知道可能阻塞的任务数量小于池的 ForkJoinPool.getParallelism 级别,否则池不能保证有足够的线程以确保进展或良好的性能。 等待任务完成并提取结果的主要方法是 join,但有几种变体:Future.get 方法支持可中断和/或定时等待完成,并使用 Future 约定报告结果。invoke 方法在语义上等同于 fork(); join(),但始终尝试在当前线程中开始执行。这些方法的“安静”形式不提取结果或报告异常。当一组任务正在执行时,可能需要延迟处理结果或异常,直到全部完成,这些形式可能很有用。方法invokeAll(有多个版本)执行最常见的并行调用形式:分叉一组任务并将它们全部合并。
在最常见的使用方式中,fork-join 对就像并行递归函数的调用(fork)和返回(join)。与其他形式的递归调用一样,应该先执行内部的返回(join)。例如,a.fork(); b.fork(); b.join(); a.join(); 比先合并 a 再合并 b 更有效率。 任务的执行状态可以在多个细节级别查询:isDone 为 true,如果任务以任何方式完成(包括任务在没有执行的情况下被取消的情况);isCompletedNormally 为 true,如果任务在没有取消或遇到异常的情况下完成;isCancelled 为 true,如果任务被取消(此时 getException 返回一个 CancellationException);isCompletedAbnormally 为 true,如果任务被取消或遇到异常,此时 getException 将返回遇到的异常或 CancellationException。
ForkJoinTask 类通常不直接子类化。相反,您子类化支持特定形式的 fork/join 处理的抽象类之一,通常是大多数不返回结果的计算的 RecursiveAction,返回结果的 RecursiveTask,以及完成的操作触发其他操作的 CountedCompleter。通常,具体的 ForkJoinTask 子类声明了组成其参数的字段,在构造函数中建立,然后定义一个使用此基类提供的控制方法以某种方式使用参数的 compute 方法。
method join 和它的变体仅在完成依赖关系是非环的情况下适用,也就是说,并行计算可以描述为有向无环图(DAG)。否则,执行可能会遇到某种形式的死锁,因为任务互相等待。然而,这个框架支持其他方法和技术(例如使用 Phaser、helpQuiesce 和 complete),这些方法可用于构造特殊子类以解决不是静态结构为 DAG 的问题。为了支持这样的用法,可以使用 setForkJoinTaskTag 或 compareAndSetForkJoinTaskTag 以短整数的值原子地对 ForkJoinTask 进行标记,并使用 getForkJoinTaskTag 进行检查。ForkJoinTask 实现不使用这些受保护的方法或标记,但它们可用于构造专门的子类。例如,并行图遍历可以使用提供的方法来避免重新访问已处理过的节点/任务。(标记的方法名称繁琐,部分是为了鼓励定义反映其使用模式的方法。)
大多数基础支持方法是final的,以防止覆盖与基础轻量级任务调度框架内在相关的实现。开发人员创建新的fork / join处理基本样式时,应至少实现protected方法exec、setRawResult和getRawResult,同时引入一种可在其子类中实现的抽象计算方法,可能依赖于该类提供的其他受保护的方法。
ForkJoinTask应该执行相对较小的计算量。大任务应该分成较小的子任务,通常通过递归分解。作为一个非常粗略的经验法则,一个任务应该执行100个以上、10000个以下的基本计算步骤,并应避免无限循环。如果任务太大,并行不能提高吞吐量。如果太小,那么内存和内部任务维护开销可能会压倒处理。
此类为Runnable和Callable提供了adapt方法,在将ForkJoinTask与其他类型的任务混合执行时可能很有用。当所有任务都是这种形式时,请考虑使用在asyncMode中构造的池。
ForkJoinTask是Serializable,这使它们可以在扩展中使用,例如远程执行框架。在执行前或执行后序列化任务是明智的,但不是在执行期间。序列化不在执行期间依赖于此。
源码解析
ForkJoinTask 类的内部文档中有一个对 class ForkJoinPool 的概述性实现。ForkJoinTasks 主要负责在向 ForkJoinWorkerThread 和 ForkJoinPool 中的方法中进行转发时维护它们的“状态”字段。
该类的方法在某种程度上层次分明: (1) 基本状态维护 (2) 执行和等待完成 (3) 还报告结果的用户级方法。 因为本文件中导出的方法按 javadocs 中的方式排列,所以这有时很难看出来。
修订说明:“Aux”字段的使用取代了以前对一个表保存异常,以及同步块和监视器等待完成的依赖。
节点用于等待完成的线程或持有抛出的异常(从不两者兼有)。等待线程以Treiber堆栈风格的方式在前面预留节点。信号者分离和释放等待者。取消的等待者试图取消连接。
示例
public class SumTask extends RecursiveTask<Long> {
private long[] numbers;
private int from;
private int to;
public SumTask(long[] numbers, int from, int to) {
this.numbers = numbers;
this.from = from;
this.to = to;
}
/**
* @return
*/
@Override
protected Long compute() {
if (to - from < 10) {
long total = 0;
for (int i = from; i <= to; i++) {
total += numbers[i];
}
return total;
} else { // Otherwise continue splitting, call recursively
int middle = (from + to) / 2;
SumTask taskLeft = new SumTask(numbers, from, middle);
SumTask taskRight = new SumTask(numbers, middle + 1, to);
taskLeft.fork();
taskRight.fork();
return taskLeft.join() + taskRight.join();
}
}
}
@Test
public void testSumTask(){
ForkJoinPool forkJoinPool = new ForkJoinPool();
long[] numbers = LongStream.rangeClosed(1, 100000000).toArray();
// Here you can call the future returned by the submit method byFuture.getGet results
Long result = forkJoinPool.invoke(new SumTask(numbers, 0, numbers.length - 1));
System.out.println("Number of active threads:"+forkJoinPool.getActiveThreadCount());
forkJoinPool.shutdown();
System.out.println("The end result:"+result);
System.out.println("Tasks stolen:"+forkJoinPool.getStealCount());
}
ForkJoinWorkerThread
概述
一个由ForkJoinPool管理的线程,执行ForkJoinTasks。这个类仅能被子类化是为了添加功能 - 没有与调度或执行相关的可重写方法。然而,您可以覆盖围绕主任务处理循环的初始化和终止方法。如果您创建了这样的子类,您还需要提供一个自定义的ForkJoinPool.ForkJoinWorkerThreadFactory,以在ForkJoinPool中使用它。
源码解析
在构造后但在处理任何任务之前初始化内部状态。如果您覆盖了此方法,则必须在方法开头调用super.onStart()。初始化需要注意:大多数字段必须具有合法的默认值,以确保其他线程尝试的访问在该线程开始处理任务之前也可以正常工作。
protected void onStart() {
}
执行与此工作线程终止相关的清理。如果您覆盖了此方法,则必须在覆盖的方法结束时调用super.onTermination。 参数: exception-由于不可恢复的错误而导致此线程中止的异常,如果正常完成则为null。
protected void onTermination(Throwable exception) {
}
ArrayBlockingQueue
概述
这是一个由数组支持的有界阻塞队列。此队列按先进先出(FIFO)顺序排列元素。队列的头是在队列中存在时间最长的元素。队列的尾是在队列中存在时间最短的元素。新元素插入到队列的尾部,队列检索操作获取队列头部的元素。 这是一个经典的“有界缓冲区”,其中一个固定大小的数组保存由生产者插入的元素和由消费者提取的元素。一旦创建,就不能更改容量。尝试将元素放入满队列将导致操作阻塞;尝试从空队列中取出元素也会进行阻塞。 此类支持可选的公平策略,用于对排队的生产者和消费者线程进行排序。默认情况下,不保证此排序。但是,使用公平性设置为true构造的队列会按FIFO顺序为线程提供访问。公平性通常会降低吞吐量,但会减少变化性并避免饥饿。 此类及其迭代器实现了集合和迭代器接口的所有可选方法。
源码分析
//队列维护的元素
final Object[] items;
//下一个要take, poll, peek 或 remove 的元素索引
int takeIndex;
//下一个put, offer或add的元素索引
int putIndex;
//队列中元素的个数
int count;
//访问时主要的使用的锁
final ReentrantLock lock;
//等待取得条件-非空
private final Condition notEmpty;
//等待put的条件-不满
private final Condition notFull;
//当前活动迭代器的共享状态,如果已知没有这样的迭代器,则为null。允许队列操作更新迭代器状态。
transient Itrs itrs;
// Internal helper methods
/**
* Increments i, mod modulus.
* Precondition and postcondition: 0 <= i < modulus.
*/
static final int inc(int i, int modulus) {
if (++i >= modulus) i = 0;
return i;
}
/**
* Decrements i, mod modulus.
* Precondition and postcondition: 0 <= i < modulus.
*/
static final int dec(int i, int modulus) {
if (--i < 0) i = modulus - 1;
return i;
}
/**
* Returns item at index i.
*/
@SuppressWarnings("unchecked")
final E itemAt(int i) {
return (E) items[i];
}
/**
* Returns element at array index i.
* This is a slight abuse of generics, accepted by javac.
*/
@SuppressWarnings("unchecked")
static <E> E itemAt(Object[] items, int i) {
return (E) items[i];
}
//元素入队,通知非空
private void enqueue(E e) {
// assert lock.isHeldByCurrentThread();
// assert lock.getHoldCount() == 1;
// assert items[putIndex] == null;
final Object[] items = this.items;
items[putIndex] = e;
if (++putIndex == items.length) putIndex = 0;
count++;
notEmpty.signal();
}
//退出队列,通知不满
private E dequeue() {
// assert lock.isHeldByCurrentThread();
// assert lock.getHoldCount() == 1;
// assert items[takeIndex] != null;
final Object[] items = this.items;
@SuppressWarnings("unchecked")
E e = (E) items[takeIndex];
items[takeIndex] = null;
if (++takeIndex == items.length) takeIndex = 0;
count--;
if (itrs != null)
itrs.elementDequeued();
notFull.signal();
return e;
}
/**
* Deletes item at array index removeIndex.
* Utility for remove(Object) and iterator.remove.
* Call only when holding lock.
*/
void removeAt(final int removeIndex) {
// assert lock.isHeldByCurrentThread();
// assert lock.getHoldCount() == 1;
// assert items[removeIndex] != null;
// assert removeIndex >= 0 && removeIndex < items.length;
final Object[] items = this.items;
if (removeIndex == takeIndex) {
// removing front item; just advance
items[takeIndex] = null;
if (++takeIndex == items.length) takeIndex = 0;
count--;
if (itrs != null)
itrs.elementDequeued();
} else {
// an "interior" remove
// slide over all others up through putIndex.
for (int i = removeIndex, putIndex = this.putIndex;;) {
int pred = i;
if (++i == items.length) i = 0;
if (i == putIndex) {
items[pred] = null;
this.putIndex = pred;
break;
}
items[pred] = items[i];
}
count--;
if (itrs != null)
itrs.removedAt(removeIndex);
}
notFull.signal();
}
/*ArrayBlockingQueue的迭代器。为了保持对puts和takes的弱一致性,我们预先读取一个槽,以免报告hasNext true但没有元素可返回。当所有索引均为负数或hasNext首次返回false时,我们将其切换为“分离”模式(允许在不使用GC的情况下立即从itrs中取消链接)。这允许迭代器完全准确地跟踪并发更新,除了用户在hasNext()返回false之后调用Iterator.remove()的角落情况。即使在这种情况下,我们也通过跟踪预期要删除的元素(在lastItem中)来确保不删除错误的元素。是的,如果在分离模式下元素由于内部插入的移动而移动,我们可能无法从队列中删除lastItem。在Java 8中添加的方法forEachRemaining类似于hasNext返回false,因为我们将其切换为分离模式,但我们将其视为对“关闭”此迭代的更强请求,并且不再支持后续的remove()。*/
private class Itr implements Iterator<E> {
/** 查找新nextItem的索引;在末尾是NON*/
private int cursor;
/** 下一次调用next()将返回的元素;如果没有则为空。 */
private E nextItem;
/** nextItem的索引;如果没有则为NONE,如果在其他地方被删除则为REMOVED */
private int nextIndex;
/** 返回的最后一个元素;如果没有或未分离则为空。 */
private E lastItem;
/** lastItem的索引,如果没有则为NONE,如果在其他地方被删除则为REMOVED */
private int lastRet;
/** takeIndex的上一个值,或者在分离时为DETACHED */
private int prevTakeIndex;
/** iters.cycles 的上一个值*/
private int prevCycles;
/** 表示“不可用”或“未定义”的特殊索引值 */
private static final int NONE = -1;
/**
表示“在其他地方删除”的特殊索引值,即通过除调用此remove()以外的操作删除。
*/
private static final int REMOVED = -2;
/** prevTakeIndex的特殊值表示"分离模式" */
private static final int DETACHED = -3;
Itr() {
lastRet = NONE;
final ReentrantLock lock = ArrayBlockingQueue.this.lock;
lock.lock();
try {
if (count == 0) {
// assert itrs == null;
cursor = NONE;
nextIndex = NONE;
prevTakeIndex = DETACHED;
} else {
final int takeIndex = ArrayBlockingQueue.this.takeIndex;
prevTakeIndex = takeIndex;
nextItem = itemAt(nextIndex = takeIndex);
cursor = incCursor(takeIndex);
if (itrs == null) {
itrs = new Itrs(this);
} else {
itrs.register(this); // in this order
itrs.doSomeSweeping(false);
}
prevCycles = itrs.cycles;
// assert takeIndex >= 0;
// assert prevTakeIndex == takeIndex;
// assert nextIndex >= 0;
// assert nextItem != null;
}
} finally {
lock.unlock();
}
}
Callable
概述
返回结果并可能抛出异常的任务。实现者定义了一个没有参数的名为 call 的单个方法。 Callable 接口类似于 Runnable,因为两者都是为其实例可能由另一个线程执行的类设计的。但是,Runnable 不返回结果,也不能抛出已检查的异常。 Executors 类包含将其他常见形式转换为 Callable 类的实用方法。
Future
概述
Future 表示异步计算的结果。提供了方法来检查计算是否完成,等待它的完成,并检索计算的结果。只有在计算完成时才能使用 get 方法检索结果,如果必要,会阻塞直到准备就绪。取消由 cancel 方法执行。还提供了其他方法来确定任务是正常完成还是被取消。一旦计算完成,就不能取消计算。如果您希望使用 Future 仅为了可取消性,但不提供可用的结果,则可以声明 Future<?> 类型,并将 null 作为基础任务的结果返回。
public interface Future<V> {
/**
尝试取消此任务的执行。如果任务已经完成或已取消,或由于其他原因无法取消,则此方法无效。否则,如果调用 cancel 时这个任务尚未开始,则此任务不应该运行。如果任务已经开始,则 mayInterruptIfRunning 参数确定是否在尝试停止任务时中断执行此任务的线程(实现知道时)。
此方法的返回值不一定表示任务是否已被取消;使用 isCancelled。
*/
boolean cancel(boolean mayInterruptIfRunning);
/**
* Returns {@code true} if this task was cancelled before it completed
* normally.
*
* @return {@code true} if this task was cancelled before it completed
*/
boolean isCancelled();
/**
如果此任务已完成,则返回 true。完成可能是由于正常终止、异常或取消——在这些情况下,此方法都会返回 true。
返回:
如果此任务已完成,则返回 true
*/
boolean isDone();
/**
如果需要,等待计算完成,然后检索其结果。
返回:
计算出的结果
*/
V get() throws InterruptedException, ExecutionException;
/**
和get()一样 并设置超时等待时间
*/
V get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
}
BlockingDeque
概述
BlockingDeque 是一种双端队列,除了支持标准的双端队列操作外,还支持在获取元素时等待队列非空,以及在存储元素时等待队列中有可用空间的阻塞操作。BlockingDeque 方法有四种形式,用于处理立即无法满足但可能在将来某个时间点满足的操作,一种抛出异常,第二种返回特殊值(根据操作为 null 或 false),第三种阻塞当前线程直到操作成功,第四种在给定最大时间限制内阻塞,超时则放弃。这些方法在下表中概括。

像任何 BlockingQueue 一样,BlockingDeque 是线程安全的,不允许使用 null 元素,并且可能(或可能不)受容量限制。BlockingDeque 实现可以直接作为 FIFO BlockingQueue 使用。从 BlockingQueue 接口继承的方法与 BlockingDeque 方法精确相等,如下表所示:

内存一致性效果:与其他并发集合一样,在将对象放入BlockingDeque之前线程中的操作发生在另一个线程中访问或删除该元素之后的操作之前。
CompletionService
概述
CompletionService是一种服务,它将新的异步任务的生成与已完成任务结果的消费分离开来。生产者提交任务执行。消费者获取已完成的任务并按照完成顺序处理它们的结果。例如,CompletionService可用于管理异步I/O,在程序或系统的一部分中提交执行读取的任务,然后在程序的另一部分中根据完成顺序处理结果。 通常,CompletionService依赖于单独的Executor来执行任务,在这种情况下,CompletionService只管理内部完成队列。ExecutorCompletionService类提供了这种方法的实现。 内存一致性效应:在向CompletionService提交任务之前线程中的操作与该任务中的操作之间存在happen-before关系,而该任务中的操作又与对应的take()成功返回后的操作之间存在happen-before关系。
源码解析
Future<V> submit(Callable<V> task); 提交一个返回值的任务执行,并返回一个Future表示该任务的待处理结果。完成后,可以获取或轮询此任务。
Future<V> submit(Runnable task, V result);CompletionService提交一个Runnable任务执行,并返回一个表示该任务的Future。完成后,可以获取或轮询此任务。
Future<V> take() throws InterruptedException; 获取并删除表示下一个完成任务的Future,如果尚未存在,则等待。
Future<V> poll();获取并删除表示下一个完成任务的Future,如果没有则返回null.
Future<V> poll(long timeout, TimeUnit unit) throws InterruptedException;获取并删除表示下一个完成任务的Future,如果没有则等待指定的时间,直到有可用的。
CyclicBarrier
概述
CyclicBarrier 是一种同步辅助工具,允许一组线程相互等待,直到它们到达公共的屏障点。CyclicBarrier 在涉及必须偶尔等待彼此的固定大小的线程组的程序中很有用。该屏障被称为周期性的,因为在释放等待的线程之后,它可以重新使用。 CyclicBarrier 支持一个可选的 Runnable 命令,该命令在每个屏障点运行一次,在最后一个线程到达之后,但在任何线程被释放之前。这个屏障动作对于在任何一方继续之前更新共享状态很有用。
CyclicBarrier 使用一种全部或无的破坏模型来处理同步尝试失败的情况:如果一个线程由于中断、失败或超时而过早离开屏障点,那么所有在该屏障点等待的其他线程也会异常地离开,通过 BrokenBarrierException(如果它们在同一时间也被中断,则会使用 InterruptedException)。 内存一致性效果:在调用 await() 之前在线程中执行的操作会发生在屏障操作的一部分之前,而这又会在其他线程中从相应的 await() 成功返回之后发生。
CyclicBarrier和CountDownLatch的区别
闭锁用于所有线程等待一个外部事件的发生,,可以认为countDown()达到设定的阈值这个事件,一种情况是等待所有子线程都执行完这个事件发生后,主线程继续执行;栅栏则是所有线程相互等待,直到所有线程都到达某一点时才打开栅栏,然后线程可以继续执行。栅栏可以重复使用
原理
class Generation
屏障的每次使用都表示为一个 generation 实例。当屏障触发或重置时,generation 会改变。使用屏障的线程可能有许多 generation,因为锁可能以非确定性的方式分配给等待的线程,但一次只能有一个是活动的(即适用于 count 的那个),所有其他的都是断开的或触发的。如果有断开,但没有后续的重置,则不需要活动的 generation。
/** 用于保护屏障入口的锁 */
private final ReentrantLock lock = new ReentrantLock();
/** 等待触发的条件 */
private final Condition trip = lock.newCondition();
/** 参与者数量 */
private final int parties;
/** 触发时要运行的命令。 */
private final Runnable barrierCommand;
/** 当前代 */
private Generation generation = new Generation();
/**
仍在等待的参与者数量。在每个 generation 上从 parties 倒数到 0。它在每个新 generation 或在断开时重置为 parties。
*/
private int count;
主要的阻塞方法
private int dowait(boolean timed, long nanos)
throws InterruptedException, BrokenBarrierException,
TimeoutException {
final ReentrantLock lock = this.lock;
lock.lock();
try {
final Generation g = generation;
if (g.broken)
throw new BrokenBarrierException();
if (Thread.interrupted()) {
breakBarrier();
throw new InterruptedException();
}
//减去当前的参与者
int index = --count;
//等于0时所有的参与者都完成了,执行构造时传的Runnable
if (index == 0) { // tripped
Runnable command = barrierCommand;
if (command != null) {
try {
command.run();
} catch (Throwable ex) {
breakBarrier();
throw ex;
}
}
//用完了,生成新的一代
nextGeneration();
return 0;
}
// 循环,直到触发、断开、中断或超时。
for (;;) {
try {
//继续等待
if (!timed)
trip.await();
else if (nanos > 0L)
nanos = trip.awaitNanos(nanos);
} catch (InterruptedException ie) {
if (g == generation && ! g.broken) {
breakBarrier();
throw ie;
} else {
// We're about to finish waiting even if we had not
// been interrupted, so this interrupt is deemed to
// "belong" to subsequent execution.
Thread.currentThread().interrupt();
}
}
if (g.broken)
throw new BrokenBarrierException();
if (g != generation)
return index;
if (timed && nanos <= 0L) {
breakBarrier();
throw new TimeoutException();
}
}
} finally {
lock.unlock();
}
}
用例
public class Solver {
final int N;
final double[][] data;
final CyclicBarrier barrier;
class Worker implements Runnable {
int myRow;
Worker(int row) { myRow = row; }
public void run() {
double[] doubles = processRow(myRow);
data[myRow]=doubles;
try {
System.out.println("线程"+Thread.currentThread().getName()+"完成");
barrier.await();
System.out.println("线程"+Thread.currentThread().getName()+"继续执行任务");
} catch (InterruptedException ex) {
return;
} catch (BrokenBarrierException ex) {
return;
}
}
private boolean done() {
return barrier.isBroken();
}
private double[] processRow(int myRow) {
double[] datum = data[myRow];
return Arrays.stream(datum).map(d->d*2).toArray();
}
}
public Solver(double[][] matrix) {
data = matrix;
N = matrix.length;
Runnable barrierAction = this::mergeRows;
barrier = new CyclicBarrier(N, barrierAction);
List<Thread> threads = new ArrayList<>(N);
for (int i = 0; i < N; i++) {
Thread thread = new Thread(new Worker(i));
threads.add(thread);
thread.start();
}
}
private void mergeRows() {
System.out.println("处理后数据================================================================");
printMatrix(data);
}
public static void printMatrix(double [][] data) {
for (double[] d : data) {
System.out.println(Arrays.toString(d));
}
}
public static void main(String[] args) {
int n =5;
double[][] rmdata = new double[n][n];
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
rmdata[i][j] = RandomUtils.nextInt(1, 10 * n);
}
}
System.out.println("处理前数据================================================================");
printMatrix(rmdata);
Solver solver = new Solver(rmdata);
}
}
locks
ReentrantLock
概述
ReentrantLock 是一种可重入的互斥锁,具有与使用 synchronized 方法和语句访问的隐式监视器锁相同的基本行为和语义,但具有扩展功能。 ReentrantLock 由上一个成功锁定但尚未解锁的线程拥有。当锁未被另一个线程拥有时,调用 lock 的线程将成功获取锁并返回。如果当前线程已经拥有该锁,则该方法将立即返回。可以使用 isHeldByCurrentThread 和 getHoldCount 方法检查此情况。 此类的构造函数接受一个可选的公平参数。在发生竞争时设置为 true 时,锁优先考虑授予最长等待线程的访问权。否则,此锁不保证任何特定的访问顺序。使用许多线程访问的公平锁的程序可能显示出较低的总吞吐量(即较慢;通常要慢得多),但具有较小的获取锁的时间差异和保证缺乏饥饿的可能性。但是,请注意,锁的公平性并不保证线程调度的公平性。因此,使用公平锁的许多线程之一可能在连续多次获得它,而其他活动线程并未进行并当前未持有该锁。另请注意,未定时的 tryLock()方法不遵守公平设置。如果锁可用,即使其他线程正在等待,它也会成功。 建议的做法是总是在调用 lock 之后立即使用 try 块,通常是在 before/after 结构中,如下所示:
class X {
private final ReentrantLock lock = new ReentrantLock();
// ...
public void m() {
lock.lock(); // block until condition holds
try {
// ... method body
} finally {
lock.unlock();
}
}
}
除了实现 Lock 接口外,此类还定义了许多用于检查锁状态的公共和保护方法。其中一些方法仅对工具和监控有用。 此类的序列化行为与内置锁的行为相同:反序列化的锁在解锁状态,而不管在序列化时的状态如何。 此锁支持同一线程的最多 2147483647 个递归锁。尝试超过此限制将导致锁定方法抛出 Error。
同步方式主要由 继承 AbstractQueuedSynchronizer的Sync实现,同时实现的公平锁和非公平锁
公平锁和非公平锁
在加锁的时候会先调用initialTryLock方法,对于公平锁来说要判断它前面有没有排队的线程才有可能获取到锁,非公平锁的情况先来尝试下获取锁,苏果获取不到才加入到队列
final void lock() {
if (!initialTryLock())
acquire(1);
}
static final class NonfairSync extends Sync {
private static final long serialVersionUID = 7316153563782823691L;
final boolean initialTryLock() {
Thread current = Thread.currentThread();
if (compareAndSetState(0, 1)) { // first attempt is unguarded
setExclusiveOwnerThread(current);
return true;
} else if (getExclusiveOwnerThread() == current) {
int c = getState() + 1;
if (c < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(c);
return true;
} else
return false;
}
/**
* Acquire for non-reentrant cases after initialTryLock prescreen
*/
protected final boolean tryAcquire(int acquires) {
if (getState() == 0 && compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
}
公平锁
/**
* Sync object for fair locks
*/
static final class FairSync extends Sync {
private static final long serialVersionUID = -3000897897090466540L;
/**
* Acquires only if reentrant or queue is empty.
*/
final boolean initialTryLock() {
Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (!hasQueuedThreads() && compareAndSetState(0, 1)) {
setExclusiveOwnerThread(current);
return true;
}
} else if (getExclusiveOwnerThread() == current) {
if (++c < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(c);
return true;
}
return false;
}
/**
* Acquires only if thread is first waiter or empty
*/
protected final boolean tryAcquire(int acquires) {
if (getState() == 0 && !hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
}
使用场景
ReadWriteLock
概述
顾名思义实现了读锁和写锁的实现。读写锁的特点是:同一时刻允许多个线程对共享资源进行读操作;同一时刻只允许一个线程对共享资源进行写操作;当进行写操作时,同一时刻其他线程的读操作会被阻塞;当进行读操作时,同一时刻所有线程的写操作会被阻塞。对于读锁而言,由于同一时刻可以允许多个线程访问共享资源,进行读操作,因此称它为共享锁;而对于写锁而言,同一时刻只允许一个线程访问共享资源,进行写操作,因此称它为排他锁。
接口方法
Lock readLock(); Lock writeLock();
实现类
jdk中有两个实现类,其中一个为StampedLock的内部类

ReentrantReadWriteLock
概述
ReentrantReadWriteLock 是一种支持类似于 ReentrantLock 语义的读写锁实现。该类具有以下属性:
- 获取顺序:该类不对锁访问的读写偏好顺序进行强制。但是,它支持可选的公平策略。
非公平模式(默认):在非公平模式下构造时,读写锁的进入顺序是不确定的,受可重入约束的限制。当连续发生竞争时,非公平锁可能会无限期地推迟一个或多个读写线程,但通常具有比公平锁更高的吞吐量。
公平模式:在公平模式下构造时,线程使用近似到达顺序策略竞争进入。当当前持有的锁被释放时,写入锁将分配给等待时间最长的单个写入线程,或者如果有一组读取线程等待时间长于所有等待写入线程,该组将被分配读取锁。如果写入锁被保持或有等待写入线程,试图获取公平读取锁(非可重入)的线程将被阻塞。线程将在当前最早等待的写入线程获取并释放写入锁之后才能获取读取锁。当然,如果一个等待的写入者放弃了等待,留下一个或多个读取线程作为队列中等待时间最长的读取线程,并且写入锁是空闲的,则这些读取线程将被分配读取锁。试图获取公平写入锁(非可重入)的线程将被阻塞,除非读取锁和写入锁都是空闲的(这意味着没有等待线程)。(注意,非阻塞 ReentrantReadWriteLock.ReadLock.tryLock() 和 ReentrantReadWriteLock.WriteLock.tryLock() 方法并不遵守此公平设置,如果可能,将立即获取锁,而不考虑等待线程。)
- 重入:这个锁允许读者和写者以 ReentrantLock 的方式重新获取读取或写入锁。在写入线程保留的所有写入锁都被释放之前,不允许非重入读取者。 另外,写入者可以获取读取锁,但是读取者不能获取写入锁。在其他应用中,当写入锁在调用或回调方法期间被保留,而这些方法在读取锁下执行读取时,重入会很有用。如果读取者试图获取写入锁,它永远不会成功。
- 锁降级:重入还允许通过获取写入锁,然后获取读取锁,再释放写入锁将写入锁降级为读取锁。但是,无法从读取锁升级为写入锁。
-
锁获取中断:读取锁和写入锁都支持在获取锁时中断。
-
Condition支持:写入锁提供了一个条件实现,它在与写入锁相关的方面与 ReentrantLock.newCondition 提供的条件实现行为一致。当然,这个条件只能用于写入锁。 读取锁不支持条件,并且 readLock().newCondition() 会抛出 UnsupportedOperationException 异常。
-
仪器:此类支持确定锁是否保留或争用的方法。这些方法旨在监视系统状态,而不是用于同步控制。
此类的序列化行为与内置锁相同:反序列化的锁总是处于解锁状态,而不管它在序列化时的状态如何。 样例用法。这是一个代码草图,显示了如何在更新缓存后执行锁降级(在非嵌套方式处理多个锁时,异常处理特别棘手):
class CachedData {
Object data;
boolean cacheValid;
final ReentrantReadWriteLock rwl = new ReentrantReadWriteLock();
void processCachedData() {
rwl.readLock().lock();
if (!cacheValid) {
// Must release read lock before acquiring write lock
rwl.readLock().unlock();
rwl.writeLock().lock();
try {
// Recheck state because another thread might have
// acquired write lock and changed state before we did.
if (!cacheValid) {
data = ...;
cacheValid = true;
}
// Downgrade by acquiring read lock before releasing write lock
rwl.readLock().lock();
} finally {
rwl.writeLock().unlock(); // Unlock write, still hold read
}
}
try {
use(data);
} finally {
rwl.readLock().unlock();
}
}
}
在某些情况下,ReentrantReadWriteLocks 可以用来提高某些类型集合的并发性。这通常只在集合期望很大,被多个读取线程访问而不是写入线程,并且涉及的操作开销超过同步开销时才有意义。例如,这是一个使用 TreeMap 的类,该类期望大并且并发访问。
class RWDictionary {
private final Map<String, Data> m = new TreeMap<>();
private final ReentrantReadWriteLock rwl = new ReentrantReadWriteLock();
private final Lock r = rwl.readLock();
private final Lock w = rwl.writeLock();
public Data get(String key) {
r.lock();
try { return m.get(key); }
finally { r.unlock(); }
}
public List<String> allKeys() {
r.lock();
try { return new ArrayList<>(m.keySet()); }
finally { r.unlock(); }
}
public Data put(String key, Data value) {
w.lock();
try { return m.put(key, value); }
finally { w.unlock(); }
}
public void clear() {
w.lock();
try { m.clear(); }
finally { w.unlock(); }
}
}
同步状态state计算
- 在AQS中,通过
int类型的全局变量state来表示同步状态,即用state来表示锁。ReentrantReadWriteLock也是通过AQS来实现锁的,但是ReentrantReadWriteLock有两把锁:读锁和写锁,它们保护的都是同一个资源,那么如何用一个共享变量来区分锁是写锁还是读锁呢?答案就是按位拆分。 - 由于state是int类型的变量,在内存中
占用4个字节,也就是32位。将其拆分为两部分:高16位和低16位,其中高16位用来表示读锁状态,低16位用来表示写锁状态。当设置读锁成功时,就将高16位加1,释放读锁时,将高16位减1;当设置写锁成功时,就将低16位加1,释放写锁时,将第16位减1。如下图所示。 - 那么如何根据state的值来判断当前锁的状态时写锁还是读锁呢?
- 假设锁当前的状态值为S,将S和16进制数
0x0000FFFF进行与运算,即S&0x0000FFFF,运算时会将高16位全置为0,将运算结果记为c,那么c表示的就是写锁的数量。如果c等于0就表示还没有线程获取锁;如果c不等于0,就表示有线程获取到了锁,c等于几就代表写锁重入了几次。 - 将S
无符号右移16位(S>>>16),得到的结果就是读锁的数量。当S>>>16得到的结果不等于0,且c也不等于0时,就表示当前线程既持有了写锁,也持有了读锁。 - 当成功获取到读锁时,如何对读锁进行加1呢?S +(1<<16)得到的结果,就是将对锁加1。释放读锁是,就进行S - (1<<16)运算。
- 当成功获取到写锁时,令S+1即表示写锁状态+1;释放写锁时,就进行S-1运算。
- 由于读锁和写锁的状态值都只占用16位,所以读锁的最大数量为 $2^{16}$-1,写锁可被重入的最大次数为$2^{16}$-1。
StampedLock
概述
带有三种模式的基于能力的锁,用于控制读/写访问。StampedLock 的状态由版本和模式组成。锁定获取方法返回一个戳记,该戳记代表并控制与锁状态相关的访问;这些方法的“尝试”版本可能会返回特殊值 0,表示无法获得访问。锁释放和转换方法需要戳记作为参数,如果它们与锁的状态不匹配,则失败。这三种模式是:
- 写入。方法 writeLock 可能会阻塞等待独占访问,返回一个戳记,该戳记可以在方法 unlockWrite 中使用来释放锁。还提供了未定时和定时版本的 tryWriteLock。当锁以写模式持有时,无法获得读锁,并且所有乐观读验证都将失败。
- 读取。方法 readLock 可能会阻塞等待非独占访问,返回一个戳记,该戳记可以在方法 unlockRead 中使用来释放锁。还提供了未定时和定时版本的 tryReadLock。
- 乐观读取。这种模式可以被认为是读锁的极弱版本,在任何时候都可能被写入者打破。在短的只读代码段中使用乐观读取模式通常会减少争用并提高吞吐量。但是,它的使用本质上是脆弱的。乐观读取部分应仅读取字段并将它们保存在局部变量中以供稍后使用。在乐观读取模式下读取的字段可能不一致,因此使用仅适用于您对数据表示足够熟悉,可以检查一致性或重复调用验证(validate)方法。例如,这些步骤通常在首次读取对象或数组引用,然后访问其中一个字段,元素或方法时是必需的。
这个类还支持有条件地在三种模式之间转换的方法。例如,方法 tryConvertToWriteLock 尝试“升级”模式,如果(1)已经在写入模式(2)在读取模式且没有其他读者或(3)在乐观读取模式且锁可用,则返回有效的写入戳记。这些方法的形式旨在帮助减少基于重试的设计中的一些代码膨胀。
StampedLocks 是为开发线程安全组件时内部使用而设计的。它们的使用依赖于对保护的数据、对象和方法的内部属性的了解。它们不是可重入的,因此加锁的主体不应调用其他可能尝试重新获取锁的未知方法(尽管您可以将戳记传递给其他可以使用或转换它的方法)。使用读锁模式的使用依赖于关联的代码段没有副作用。未验证的乐观读取部分不能调用可能不容忍潜在不一致性的未知方法。戳记使用有限表示,不是加密安全的(即,有效的戳记可能可以猜测)。在连续运行一年后(不晚于此时间),戳记可能会回收。如果一个戳记在此期间没有使用或验证就被保留,则可能无法正确验证。StampedLocks 可以序列化,但始终反序列化为初始未锁定状态,因此他们不适用于远程锁定。
StampedLocks的调度策略不一定总是倾向于优先读取者或写入者。所有的“尝试”方法都是尽力而为的,不一定符合任何调度或公平策略。任何用于获取或转换锁的“尝试”方法的零返回值并不携带有关锁状态的任何信息;随后的调用可能会成功。因为它支持多个锁模式的协调使用,所以这个类没有直接实现Lock或ReadWriteLock接口。但是,在需要仅相关功能集的应用程序中,可以将StampedLock视为ReadLock,asWriteLock或asReadWriteLock。
内存同步。 在任何模式下成功锁定的方法具有与锁定操作相同的内存同步效果,如《Java语言规范》第17章中所述。 在写模式下成功解锁的方法具有与解锁操作相同的内存同步效果。 在乐观读取用法中,在最近的写模式解锁操作之前的操作在validate返回true之前被保证发生在之后的操作之前; 否则,无法保证在tryOptimisticRead和validate之间的读取获得一致的快照。 示例用法。 以下是维护简单二维点的类的一些用法习惯用法。 示例代码演示了一些try / catch约定,即使它们在此处并不严格必要,因为它们的体内不会发生异常。
class Point {
private double x, y;
private final StampedLock sl = new StampedLock();
// an exclusively locked method
void move(double deltaX, double deltaY) {
long stamp = sl.writeLock();
try {
x += deltaX;
y += deltaY;
} finally {
sl.unlockWrite(stamp);
}
}
// a read-only method
// upgrade from optimistic read to read lock
double distanceFromOrigin() {
long stamp = sl.tryOptimisticRead();
try {
retryHoldingLock: for (;; stamp = sl.readLock()) {
if (stamp == 0L)
continue retryHoldingLock;
// possibly racy reads
double currentX = x;
double currentY = y;
if (!sl.validate(stamp))
continue retryHoldingLock;
return Math.hypot(currentX, currentY);
}
} finally {
if (StampedLock.isReadLockStamp(stamp))
sl.unlockRead(stamp);
}
}
// upgrade from optimistic read to write lock
void moveIfAtOrigin(double newX, double newY) {
long stamp = sl.tryOptimisticRead();
try {
retryHoldingLock: for (;; stamp = sl.writeLock()) {
if (stamp == 0L)
continue retryHoldingLock;
// possibly racy reads
double currentX = x;
double currentY = y;
if (!sl.validate(stamp))
continue retryHoldingLock;
if (currentX != 0.0 || currentY != 0.0)
break;
stamp = sl.tryConvertToWriteLock(stamp);
if (stamp == 0L)
continue retryHoldingLock;
// exclusive access
x = newX;
y = newY;
return;
}
} finally {
if (StampedLock.isWriteLockStamp(stamp))
sl.unlockWrite(stamp);
}
}
// upgrade read lock to write lock
void moveIfAtOrigin2(double newX, double newY) {
long stamp = sl.readLock();
try {
while (x == 0.0 && y == 0.0) {
long ws = sl.tryConvertToWriteLock(stamp);
if (ws != 0L) {
stamp = ws;
x = newX;
y = newY;
break;
}
else {
sl.unlockRead(stamp);
stamp = sl.writeLock();
}
}
} finally {
sl.unlock(stamp);
}
}
}
AbstractQueuedLongSynchronizer
概述
在 AbstractQueuedSynchronizer 版本中,同步状态被维护为 long。除了所有与状态相关的参数和结果都定义为 long 而不是 int 之外,这个类与 AbstractQueuedSynchronizer 的结构,属性和方法完全相同。当创建需要 64 位状态的同步器(如多级锁和屏障)时,这个类可能会很有用。
AbstractQueuedSynchronizer
概述
提供一个框架,用于实现依赖于先进先出 (FIFO) 等待队列的阻塞锁和相关同步器(信号量、事件等)。此类旨在成为大多数依赖单个原子 int 值来表示状态的同步器的有用基础。子类必须定义更改此状态的受保护方法,以及定义该状态在获取或释放此对象方面的含义。鉴于这些,此类中的其他方法执行所有排队和阻塞机制。子类可以维护其他状态字段,但只有使用方法getState,setState和compareAndSetState操作的原子更新的int值才会被跟踪同步。子类应定义为非公共内部帮助程序类,用于实现其封闭类的同步属性。 类抽象队列同步器不实现任何同步接口。相反,它定义了诸如 acquireInterruptibly 之类的方法,具体锁和相关同步器可以根据需要调用这些方法来实现其公共方法。此类支持默认独占模式和共享模式之一或同时支持。以独占模式获取时,其他线程尝试的获取无法成功。由多个线程获取的共享模式可能会(但不需要)成功。此类不“理解”这些差异,除非在机械意义上,当共享模式获取成功时,下一个等待线程(如果存在)也必须确定它是否可以获取。在不同模式下等待的线程共享相同的 FIFO 队列。通常,实现子类仅支持其中一种模式,但这两种模式都可以发挥作用,例如在 ReadWriteLock 中。仅支持独占模式或仅支持共享模式的子类不需要定义支持未使用模式的方法。此类定义了一个嵌套的 AbstractQueuedSyncr.ConditionObject 类,该类可由支持独占模式的子类用作条件实现,该方法 isHeldExclusive 报告同步是否相对于当前线程以独占方式保持,使用当前 getState 值调用的方法释放完全释放此对象,并在给定此保存的状态值的情况下获取,最终将此对象还原到其先前获取的状态。否则,没有 AbstractQueuedSyncer 方法会创建这样的条件,因此如果无法满足此约束,请不要使用它。AbstractQueuedSyncr.ConditionObject 的行为当然取决于其同步器实现的语义。此类为内部队列提供检查、检测和监视方法,并为条件对象提供类似的方法。这些可以根据需要导出到类中,使用AbstractQueuedSyncr的同步机制。此类的序列化仅存储基础原子整数维护状态,因此反序列化的对象具有空线程队列。需要可序列化性的典型子类将定义一个 readObject 方法,该方法在反序列化时将其还原为已知的初始状态。
同步器的设计是基于模板方法模式的,也就是说,使用者需要继承同步器并重写指定的 方法,随后将同步器组合在自定义同步组件的实现中,并调用同步器提供的模板方法,而这些 模板方法将会调用使用者重写的方法。 重写同步器指定的方法时,需要使用同步器提供的如下3个方法来访问或修改同步状态。
·getState():获取当前同步状态。
·setState(int newState):设置当前同步状态。
·compareAndSetState(int expect,int update):使用CAS设置当前状态,该方法能够保证状态 设置的原子性.
AbstractOwnableSynchronizer
概述
可能由线程独占拥有的同步器。此类为创建锁和相关同步器提供了基础,这些同步器可能需要所有权的概念。类本身不管理或使用此信息。但是,子类和工具可以使用适当维护的值来帮助控制和监视访问并提供诊断。java中以下类继承了该类

源码
public abstract class AbstractOwnableSynchronizer
implements java.io.Serializable {
/** Use serial ID even though all fields transient. */
private static final long serialVersionUID = 3737899427754241961L;
/**
* Empty constructor for use by subclasses.
*/
protected AbstractOwnableSynchronizer() { }
/**
* The current owner of exclusive mode synchronization.
*/
private transient Thread exclusiveOwnerThread;
/**
* Sets the thread that currently owns exclusive access.
* A {@code null} argument indicates that no thread owns access.
* This method does not otherwise impose any synchronization or
* {@code volatile} field accesses.
* @param thread the owner thread
*/
protected final void setExclusiveOwnerThread(Thread thread) {
exclusiveOwnerThread = thread;
}
/**
* Returns the thread last set by {@code setExclusiveOwnerThread},
* or {@code null} if never set. This method does not otherwise
* impose any synchronization or {@code volatile} field accesses.
* @return the owner thread
*/
protected final Thread getExclusiveOwnerThread() {
return exclusiveOwnerThread;
}
}
维护了一个transient的线程,用来标记独占模式下的拥有线程,并提供set和get方法
LockSupport
概述
用于创建锁和其他同步类的基本线程阻塞基元。
此类与使用它的每个线程关联一个许可证(在信号量类的意义上)。如果许可证可用,park调用将立即返回,并在此过程中消耗许可;否则可能会阻止。如果许可证尚不可用,则调用unpark即可获得许可证。(与信号量不同,许可证不会累积。最多有一个。)可靠的使用需要使用volatile(或原子)变量来控制何时park或unpark。对这些方法的调用的顺序是相对于volatile变量访问维护的,但不是必须的对于非volatile变量访问。方法park和unpark提供了有效的阻塞和取消阻塞线程的方法,这些线程不会遇到导致已弃用的方法Thread.susure和Thread.resume无法用于以下目的的问题:由于许可,一个调用park的线程和另一个试图unpark它的线程之间的竞争将保持活动状态。此外,如果调用方的线程中断,park方法将返回,并且支持超时版本。Park 方法也可以在任何其他时间返回,“无缘无故”,因此通常必须在返回时重新检查条件的循环中调用。从这个意义上说,park方法是“忙碌等待”的优化,不会浪费太多时间自旋,但必须与unpark配对才能有效。三种形式的公园还分别支持阻止程序对象参数。在线程被阻塞时记录此对象,以允许监视和诊断工具识别线程被阻塞的原因。(此类工具可以使用方法getBlocker(Thread)访问阻止程序。强烈建议使用这些表单,而不是没有此参数的原始表单。在锁实现中作为阻止程序提供的正常参数是这样的。这些方法旨在用作创建更高级别的同步实用程序的工具,并且它们本身对大多数并发控制应用程序没有用处。park方法设计仅用于形式的结构
while (!canProceed()) {
// ensure request to unpark is visible to other threads
...
LockSupport.park(this);
}
在调用park之前,发布unpark请求的线程的任何操作都不会涉及锁定或阻止。由于每个线程只有一个许可证,因此对 park 的任何中间使用(包括隐式通过类加载)都可能导致线程无响应(“丢失的 unpark”)。
方法
-
park() 阻塞当前线程,指导发生一下情况时被唤醒:
- 其他线程以当前线程调用unpark方法
- 其他线程打断当前线程
- 虚假调用返回
-
parkNanos(long nanos) 与park一样,唤醒与之不一样的是多了一种,即等待特定的纳秒时间唤醒。nanos<=0时不执行任何操作
-
park(Object blocker) 可以设置blocker,在诊断问题时可以知道park的原因
-
parkUntil(long deadline) 阻塞当前线程,直到传的deadline时间
Condition
概述
条件将对象监视器方法(等待、通知和通知全部)分解为不同的对象,通过将它们与任意 Lock 实现相结合,为每个对象提供多个等待集的效果。Lock 取代了同步方法和语句的使用,条件取代了对象监视器方法的使用。条件(也称为条件队列或条件变量)为一个线程提供了一种暂停执行(“等待”)的方法,直到另一个线程通知某个状态条件现在可能为真。由于对此共享状态信息的访问发生在不同的线程中,因此必须对其进行保护,因此某种形式的锁与条件相关联。等待条件提供的关键属性是它以原子方式释放关联的锁并挂起当前线程,就像 Object.wait 一样。条件实例本质上绑定到锁。要获取特定 Lock 实例的条件实例,请使用其 newCondition() 方法。例如,假设我们有一个支持放置和获取方法的有界缓冲区。如果尝试在空缓冲区上获取,则线程将阻塞,直到项目可用;如果在已满缓冲区上尝试放置,则线程将阻塞,直到有空间可用。我们希望继续等待放置线程并将线程放在单独的等待集中,以便我们可以使用在缓冲区中可用项目或空间时仅通知单个线程的优化。这可以使用两个条件实例来实现。
class BoundedBuffer<E> {
final Lock lock = new ReentrantLock();
final Condition notFull = lock.newCondition();
final Condition notEmpty = lock.newCondition();
final Object[] items = new Object[100];
int putptr, takeptr, count;
public void put(E x) throws InterruptedException {
lock.lock();
try {
while (count == items.length)
notFull.await();
items[putptr] = x;
if (++putptr == items.length) putptr = 0;
++count;
notEmpty.signal();
} finally {
lock.unlock();
}
}
public E take() throws InterruptedException {
lock.lock();
try {
while (count == 0)
notEmpty.await();
E x = (E) items[takeptr];
if (++takeptr == items.length) takeptr = 0;
--count;
notFull.signal();
return x;
} finally {
lock.unlock();
}
}
}
(java.util.concurrent.ArrayBlockingQueue 类提供了此功能,因此没有理由实现此示例用法类。条件实现可以提供不同于对象监视器方法的行为和语义,例如保证通知的顺序,或者在执行通知时不需要保持锁定。如果实现提供了这样的专用语义,则实现必须记录这些语义。请注意,Condition 实例只是普通对象,它们本身可以用作同步语句中的目标,并且可以调用自己的监视器等待和通知方法。获取条件实例的监视器锁或使用其监视方法与获取与该条件关联的锁或使用其等待和信号方法没有指定的关系。为避免混淆,建议您永远不要以这种方式使用 Condition 实例,除非在它们自己的实现中。除非另有说明,否则为任何参数传递 null 值都将导致引发 NullPointerException。
实现注意事项
在等待条件时,通常允许发生“虚假唤醒”,作为对基础平台语义的让步。这对大多数应用程序几乎没有实际影响,因为条件应始终在循环中等待,测试正在等待的状态谓词。实现可以自由地消除虚假唤醒的可能性,但建议应用程序程序员始终假设它们可能发生,因此始终在循环中等待。三种形式的条件等待(可中断、不可中断和定时)在某些平台上的实现难易程度和性能特征方面可能有所不同。特别是,可能难以提供这些功能并维护特定的语义(如订购保证)。此外,中断线程实际挂起的能力可能并不总是在所有平台上实现的。因此,实现不需要为所有三种形式的等待定义完全相同的保证或语义,也不需要支持线程实际挂起的中断。实现需要清楚地记录每个等待方法提供的语义和保证,当实现确实支持线程挂起中断时,它必须遵守此接口中定义的中断语义。由于中断通常意味着取消,并且中断检查通常不频繁,因此实现可能倾向于响应中断而不是正常方法返回。即使可以证明中断发生在可能已取消阻止线程的另一个操作之后,也是如此。实现应记录此行为。
方法说明

- await 使当前线程等待,直到发出信号或中断。与此条件关联的锁以原子方式释放,当前线程因线程调度目的而被禁用并处于休眠状态,直到发生以下四种情况之一:其他线程调用此条件的信号方法,并且当前线程恰好被选为要唤醒的线程;或某个其他线程为此条件调用 signalAll 方法;或者其他一些线程中断当前线程,支持线程挂起中断;或发生“虚假唤醒”。在所有情况下,在此方法可以返回之前,当前线程必须重新获取与此条件关联的锁。当线程返回时,它保证保持此锁。如果当前线程:在进入此方法时设置了中断状态;或者在等待时中断,支持线程挂起中断,则抛出中断异常,清除当前线程的中断状态。在第一种情况下,没有指定是否在释放锁之前进行中断测试。实现注意事项 调用此方法时,假定当前线程持有与此条件关联的锁。由实施来确定是否是这种情况,如果不是,如何响应。通常,将引发异常(例如 IllegalMonitorStateException),并且实现必须记录该事实。实现可以倾向于响应中断,而不是响应信号的正常方法返回。在这种情况下,实现必须确保将信号重定向到另一个等待线程(如果有)。
-
awaitUninterruptibly()
使当前线程等待,直到发出信号。与此条件关联的锁以原子方式释放,当前线程出于线程调度目的而被禁用并处于休眠状态,直到发生以下三种情况之一:其他线程为此条件调用信号方法,并且当前线程恰好被选为要唤醒的线程;或某个其他线程为此条件调用 signalAll 方法;或发生“虚假唤醒”。在所有情况下,在此方法可以返回之前,当前线程必须重新获取与此条件关联的锁。当线程返回时,它保证保持此锁。如果当前线程在进入此方法时设置了中断状态,或者在等待时中断,则将继续等待,直到发出信号。当它最终从此方法返回时,仍将设置其中断状态。实现注意事项 调用此方法时,假定当前线程持有与此条件关联的锁。由实现来确定是否是这种情况,如果不是,如何响应。通常,将引发异常(例如 IllegalMonitorStateException),并且实现必须记录该事实。
-
awaitNanos(long nanosTimeout)
该方法在返回时给定提供的 nanosTimeout 值的情况下返回剩余等待的纳秒数的估计值,如果超时,则返回小于或等于零的值。此值可用于确定在等待返回但等待条件仍未成立的情况下是否重新等待以及重新等待多长时间。此方法的典型用法采用以下形式
boolean aMethod(long timeout, TimeUnit unit)
throws InterruptedException {
long nanosRemaining = unit.toNanos(timeout);
lock.lock();
try {
while (!conditionBeingWaitedFor()) {
if (nanosRemaining <= 0L)
return false;
nanosRemaining = theCondition.awaitNanos(nanosRemaining);
}
// ...
return true;
} finally {
lock.unlock();
}
}
设计说明:此方法需要纳秒参数,以避免在报告剩余时间时出现截断错误。这种精度损失将使程序员难以确保总等待时间不会系统地短于发生重新等待时指定的时间。实现注意事项 调用此方法时,假定当前线程持有与此条件关联的锁。由实施来确定是否是这种情况,如果不是,如何响应。通常,将引发异常(例如 IllegalMonitorStateException),并且实现必须记录该事实。实现可以倾向于响应中断,而不是响应信号的正常方法返回,或者指示指定等待时间的经过。在任何一种情况下,实现都必须确保将信号重定向到另一个等待线程(如果有)。参数:nanosTimeout – 等待的最长时间,以纳秒为单位 返回:估计 nanosTimeout 值减去从此方法返回时等待所花费的时间。正值可用作对此方法的后续调用的参数,以完成等待所需时间。小于或等于零的值表示没有剩余时间。
-
await(long time, TimeUnit unit)
使当前线程等待,直到发出信号或中断,或者指定的等待时间过去。此方法在行为上等效于:awaitNanos(unit.toNanos(time)) > 0
-
awaitUntil(Date deadline)
在等待时间之内可以被其它线程唤醒,等待时间一过该线程会自动唤醒,和别的线程争抢锁资源
-
void signal()
唤醒一个等待线程。如果有任何线程正在等待此条件,则选择一个线程进行唤醒。然后,该线程必须在从 await 返回之前重新获取锁。实现注意事项 在调用此方法时,实现可能(并且通常确实)要求当前线程持有与此条件关联的锁。实现必须记录此前提条件以及未保持锁时采取的任何操作。通常,将引发异常,例如 IllegalMonitorStateException。
-
void signalAll()
唤醒所有等待的线程。如果有任何线程正在等待这种情况,则它们都将被唤醒。每个线程必须重新获取锁,然后才能从 await 返回。
Lock
概述
Lock实现提供了比使用synchronized方法和语句可以获得的更广泛的锁定操作。 它们允许更灵活的结构,可能具有完全不同的属性,并且可能支持多个关联的Condition对象。
锁是用于控制多个线程对共享资源的访问的工具。 通常,锁提供对共享资源的独占访问:一次只有一个线程可以获取锁,并且对共享资源的所有访问都需要首先获取锁。 但是,某些锁可能允许并发访问共享资源,例如ReadWriteLock的读锁定。
使用synchronized方法或语句可以访问与每个对象关联的隐式监视器锁,但强制所有锁获取和释放以块结构方式发生:当获取多个锁时,它们必须以相反的顺序释放,并且所有锁必须在获取它们的相同词法范围内释放。
虽然synchronized方法和语句的作用域机制使得使用监视器锁更容易编程,并且有助于避免许多涉及锁的常见编程错误,但有时您需要以更灵活的方式使用锁。 例如,一些用于遍历并发访问的数据结构的算法需要使用“hand-hand-hand”或“chain locking”:获取节点A的锁,然后获取节点B,然后释放A并获取C,然后释放B并获得D等。 Lock接口的实现允许通过允许在不同范围内获取和释放锁来允许使用这种技术,并允许以任何顺序获取和释放多个锁。
随着这种增加的灵活性带来额外的责 缺少块结构锁定会删除synchronized方法和语句发生的锁定的自动释放。 在大多数情况下,应使用以下习语:
Lock l = ...; l.lock(); try { // access the resource protected by this lock } finally { l.unlock(); }
当锁定和解锁发生在不同的范围内时,必须注意确保在保持锁定时执行的所有代码都受try-finally或try-catch保护,以确保在必要时释放锁定。
Lock实现通过提供非阻塞尝试获取锁( tryLock() ),尝试获取可以被中断的锁( lockInterruptibly() ,以及尝试获取可以锁定的锁)来提供使用synchronized方法和语句的附加功能超时( tryLock(long, TimeUnit) )。
Lock类还可以提供与隐式监视器锁完全不同的行为和语义,例如保证排序,非重入使用或死锁检测。 如果实现提供了这样的专用语义,那么实现必须记录那些语义。
请注意, Lock实例只是普通对象,它们本身可以用作synchronized语句中的目标。 获取Lock实例的监视器锁定与调用该实例的任何lock()方法没有指定的关系。 为避免混淆,建议您不要以这种方式使用Lock实例,除非在他们自己的实现中。
除非另有说明, null为任何参数传递null值将导致抛出NullPointerException 。
内存同步
所有Lock实现必须强制执行内置监视器锁提供的相同内存同步语义,如Chapter 17 of The Java™ Language Specification中所述 :
- 成功的
lock操作具有与成功锁定操作相同的内存同步效果。 - 成功的
unlock操作具有与成功解锁操作相同的内存同步效果。
不成功的锁定和解锁操作以及重入锁定/解锁操作不需要任何内存同步效果。
实施注意事项
锁定获取的三种形式(可中断,不可中断和定时)可能在性能特征,排序保证或其他实现质量方面有所不同。 此外,在给定的Lock类中可能无法中断正在进行的锁定获取的能力。 因此,不需要实现为所有三种形式的锁获取定义完全相同的保证或语义,也不需要支持正在进行的锁获取的中断。 需要一种实现来清楚地记录每种锁定方法提供的语义和保证。 它还必须遵守此接口中定义的中断语义,以支持锁获取的中断:完全或仅在方法入口上。
由于中断通常意味着取消,并且中断检查通常不常见,因此实现可以有利于响应正常方法返回的中断。 即使可以显示在另一个操作可能已取消阻塞线程之后发生中断,也是如此。 实现应记录此行为。
实现类

方法解读
该类主要有六个方法, lock 和unlock 是成对出现的。tryLock与lock不同的点:
lock 在使用中,强制上锁,不会被其他线程interrupt住,拿不到锁会一直等待;而trylock可以在规定的interval时间内,尝试获取锁,如果获取到,返回true,否则false。trylock随时可以被其他线程interrupt中断掉。和 lock 方法类似,当有可用锁时会直接得到锁并立即返回,如果没有可用锁会一直等待直到获取锁,但和 lock 方法不同,lockInterruptibly 方法在等待获取时,如果遇到线程中断会放弃获取锁.
AbstractExecutorService
概述
提供ExecutorService执行方法的默认实现。该类使用由newTaskFor返回的RunnableFuture实现submit、invokeAny和invokeAll方法,默认为此包中提供的FutureTask类。例如,submit(Runnable)的实现创建并返回一个关联的RunnableFuture。子类可以重写newTaskFor方法,返回除FutureTask之外的RunnableFuture实现。
源码解析
invokeAny方法允许您执行可调用任务的集合,并返回第一个完成任务的结果。当您希望在并行中执行多个任务并返回第一个完成的结果时,该方法很有用,同时丢弃其他结果。也可以用它在一个任务完成后取消剩余任务。
private <T> T doInvokeAny(Collection<? extends Callable<T>> tasks,
boolean timed, long nanos)
throws InterruptedException, ExecutionException, TimeoutException {
if (tasks == null)
throw new NullPointerException();
int ntasks = tasks.size();
if (ntasks == 0)
throw new IllegalArgumentException();
ArrayList<Future<T>> futures = new ArrayList<>(ntasks);
ExecutorCompletionService<T> ecs =
new ExecutorCompletionService<T>(this);
// For efficiency, especially in executors with limited
// parallelism, check to see if previously submitted tasks are
// done before submitting more of them. This interleaving
// plus the exception mechanics account for messiness of main
// loop.
try {
// Record exceptions so that if we fail to obtain any
// result, we can throw the last exception we got.
ExecutionException ee = null;
final long deadline = timed ? System.nanoTime() + nanos : 0L;
Iterator<? extends Callable<T>> it = tasks.iterator();
// Start one task for sure; the rest incrementally
futures.add(ecs.submit(it.next()));
--ntasks;
int active = 1;
for (;;) {
Future<T> f = ecs.poll();
if (f == null) {
//如果没有获取到,重新提交
if (ntasks > 0) {
--ntasks;
futures.add(ecs.submit(it.next()));
++active;
}
else if (active == 0)
break;
//等待特定时间
else if (timed) {
f = ecs.poll(nanos, NANOSECONDS);
if (f == null)
throw new TimeoutException();
nanos = deadline - System.nanoTime();
}
else
f = ecs.take();
}
if (f != null) {
--active;
try {
//如果有一个执行完了,就返回结果
return f.get();
} catch (ExecutionException eex) {
ee = eex;
} catch (RuntimeException rex) {
ee = new ExecutionException(rex);
}
}
}
if (ee == null)
ee = new ExecutionException();
throw ee;
} finally {
//取消剩余任务
cancelAll(futures);
}
}
invokeAll方法允许您执行可调用任务的集合,并返回表示每个任务结果的Future对象的列表。当你想并行执行多个任务并等待它们全部完成之前处理结果时,这种方法很有用。它还可以用来在一个任务完成后取消剩余任务。返回的Future对象列表可用于检查每个任务的状态并在可用时检索结果。
public <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks)
throws InterruptedException {
if (tasks == null)
throw new NullPointerException();
ArrayList<Future<T>> futures = new ArrayList<>(tasks.size());
try {
//执行每个任务
for (Callable<T> t : tasks) {
RunnableFuture<T> f = newTaskFor(t);
futures.add(f);
execute(f);
}
for (int i = 0, size = futures.size(); i < size; i++) {
Future<T> f = futures.get(i);
//如果没有完成,一直阻塞获取
if (!f.isDone()) {
try { f.get(); }
catch (CancellationException | ExecutionException ignore) {}
}
}
//返回所有的执行结果
return futures;
} catch (Throwable t) {
cancelAll(futures);
throw t;
}
}
RunnableFuture
概述
Future 是Runnable。run 方法的成功执行导致 Future 的完成,并允许访问其结果。
原理
public interface RunnableFuture<V> extends Runnable, Future<V> {
//将此 Future 设置为其计算的结果,除非已取消。
void run();
}
ScheduledThreadPoolExecutor
概述
ScheduledThreadPoolExecutor 是一个可以在给定延迟后运行命令或定期执行命令的线程池执行器。当需要多个工作线程或需要 ThreadPoolExecutor(该类继承)的额外灵活性或功能时,该类比 java.util.Timer 更可取。延迟任务在启用之后立即执行,但没有任何实时保证在启用之后何时开始。按照提交顺序的首先进先出(FIFO)顺序启用恰好相同执行时间的任务。当提交的任务在运行之前被取消时,执行被抑制。默认情况下,此类取消的任务不会自动从工作队列中删除,直到其延迟过期。虽然这可以进一步检查和监视,但它也可能导致取消任务的无限保留。为避免这种情况,使用 setRemoveOnCancelPolicy 使任务在取消时立即从工作队列中删除。使用scheduleAtFixedRate或scheduleWithFixedDelay安排的周期性任务的连续执行不会相互重叠。虽然不同的执行可能由不同的线程执行,但先前执行的影响先于后续执行。此类继承自ThreadPoolExecutor,但一些继承的调整方法对其无用。特别是,由于它使用corePoolSize线程和无界队列作为固定大小的池,因此对maximumPoolSize的调整没有有用的效果。此外,将corePoolSize设置为零或使用allowCoreThreadTimeOut几乎永远不是一个好主意,因为这可能会使池中没有线程处理任务,一旦它们成为可运行的。与ThreadPoolExecutor一样,如果未另行指定,此类使用Executors.defaultThreadFactory作为默认线程工厂,并使用ThreadPoolExecutor.AbortPolicy作为默认的拒绝执行处理程序。此类重写了execute和submit方法,以生成内部ScheduledFuture对象来控制每个任务的延迟和调度。为了保持功能,在子类中对这些方法的任何进一步重写都必须调用超类版本,这实际上禁用了额外的任务自定义。然而,此类提供了可用于自定义执行execute、submit、schedule、scheduleAtFixedRate和scheduleWithFixedDelay命令的具体任务类型的保护扩展方法decorateTask(分别针对Runnable和Callable)。默认情况下,ScheduledThreadPoolExecutor使用继承FutureTask的任务类型。然而,可以使用形如的子类修改或替换它:
public class CustomScheduledExecutor extends ScheduledThreadPoolExecutor {
static class CustomTask<V> implements RunnableScheduledFuture<V> { ... }
protected <V> RunnableScheduledFuture<V> decorateTask(
Runnable r, RunnableScheduledFuture<V> task) {
return new CustomTask<V>(r, task);
}
protected <V> RunnableScheduledFuture<V> decorateTask(
Callable<V> c, RunnableScheduledFuture<V> task) {
return new CustomTask<V>(c, task);
}
// ... add constructors, etc.
}
Flow
概述
这些接口对应于反应流规范。它们适用于并发和分布式异步设置:所有(七个)方法都是以 void "单向"消息样式定义的。通信依赖于一种简单的流量控制形式(方法Flow.Subscription.request),可用于避免“推送”系统中可能发生的资源管理问题。
示例。Flow.Publisher通常定义自己的Flow.Subscription实现,在subscribe方法中构造一个并将其发送给调用的Flow.Subscriber。它异步发布项目给订阅者,通常使用Executor。例如,这是一个非常简单的发布者,它只在请求时向单个订阅者发布单个TRUE项。因为订阅者仅接收单个项目,所以该类不使用大多数实现中需要的缓冲和排序控制(例如SubmissionPublisher)
class OneShotPublisher implements Publisher<Boolean> {
private final ExecutorService executor = ForkJoinPool.commonPool(); // daemon-based
private boolean subscribed; // true after first subscribe
public synchronized void subscribe(Subscriber<? super Boolean> subscriber) {
if (subscribed)
subscriber.onError(new IllegalStateException()); // only one allowed
else {
subscribed = true;
subscriber.onSubscribe(new OneShotSubscription(subscriber, executor));
}
}
static class OneShotSubscription implements Subscription {
private final Subscriber<? super Boolean> subscriber;
private final ExecutorService executor;
private Future<?> future; // to allow cancellation
private boolean completed;
OneShotSubscription(Subscriber<? super Boolean> subscriber,
ExecutorService executor) {
this.subscriber = subscriber;
this.executor = executor;
}
public synchronized void request(long n) {
if (!completed) {
completed = true;
if (n <= 0) {
IllegalArgumentException ex = new IllegalArgumentException();
executor.execute(() -> subscriber.onError(ex));
} else {
future = executor.submit(() -> {
subscriber.onNext(Boolean.TRUE);
subscriber.onComplete();
});
}
}
}
public synchronized void cancel() {
completed = true;
if (future != null) future.cancel(false);
}
}
}
Flow.Subscriber安排请求和处理项目。除非请求,否则不会发出项目(调用Flow.Subscriber.onNext),但可以请求多个项目。许多Subscriber实现可以以下面示例中的风格安排这一点,其中缓冲区大小为1,较大的大小通常允许更有效的重叠处理,并且通信更少; 例如,值为64时,这将总体未完成请求保持在32和64之间。由于特定Flow.Subscription的Subscriber方法调用严格有序,因此这些方法不需要使用锁或volatiles,除非Subscriber维护多个Subscriptions(在这种情况下,最好定义多个Subscriber,每个都有自己的Subscription)。
class SampleSubscriber<T> implements Subscriber<T> {
final Consumer<? super T> consumer;
Subscription subscription;
final long bufferSize;
long count;
SampleSubscriber(long bufferSize, Consumer<? super T> consumer) {
this.bufferSize = bufferSize;
this.consumer = consumer;
}
public void onSubscribe(Subscription subscription) {
long initialRequestSize = bufferSize;
count = bufferSize - bufferSize / 2; // re-request when half consumed
(this.subscription = subscription).request(initialRequestSize);
}
public void onNext(T item) {
if (--count <= 0)
subscription.request(count = bufferSize - bufferSize / 2);
consumer.accept(item);
}
public void onError(Throwable ex) { ex.printStackTrace(); }
public void onComplete() {}
}
默认的defaultBufferSize值可能为选择请求大小和容量的流组件提供有用的参考,或者当不需要流量控制时,可以请求无限数量的项目。
源码解析
Publisher是一种生产物品(和相关控制消息)的生产者,被Subscriber接收。每个当前的Flow.Subscriber按相同顺序接收相同的物品(通过onNext方法),除非遇到丢弃或错误。如果Publisher遇到不允许向Subscriber发布物品的错误,该Subscriber将收到onError,然后不再收到其他消息。否则,当已知不会向其发送更多消息时,订阅者将收到onComplete。Publishers确保每个订阅的Subscriber方法调用严格按happens-before顺序排序。Publishers可能在丢弃(由于资源限制而未能发布物品)是否被视为不可恢复错误的策略上有所不同。Publishers也可能在Subscribers是否接收在它们订阅之前生产或可用的物品上有所不同。 类型参数: <T> - 发布的物品类型
@FunctionalInterface
public static interface Publisher<T> {
如果可能的话,添加给定的订阅者。如果已经订阅,或尝试订阅因政策违规或错误而失败,则会调用订阅者的onError方法,并传入一个IllegalStateException。否则,会调用订阅者的onSubscribe方法,并传入一个新的Flow.Subscription。订阅者可以通过调用此Subscription的request方法启用接收项目,并可以通过调用其cancel方法取消订阅。
参数:
订阅者-订阅者
引发:
NullPointerException-如果订阅者为空
public void subscribe(Subscriber<? super T> subscriber);
}
一个消息接收器。此接口中的方法对于每个Flow.Subscription都按严格顺序调用。类型参数:<T> - 订阅项目类型。
public static interface Subscriber<T> {
在调用给定订阅的任何其他订阅者方法之前调用的方法。 如果此方法抛出异常,则保证的结果行为不能保证,但
可能导致未建立订阅或取消订阅。
通常,此方法的实现调用subscription.request以启用接收项目。
参数:subscription - 新订阅
public void onSubscribe(Subscription subscription);
当订阅的下一项出现时,将调用此方法。如果此方法引发异常,则不保证结果行为,但可能会导致取消订阅。
参数: 项目-项目。
public void onNext(T item);
方法在出版商或订阅遇到无法恢复的错误时调用,在此之后订阅不再调用其他订阅者方法。如果此方法本身抛出异
常,则结果行为未定义。
参数:throwable - 异常
public void onError(Throwable throwable);
这个方法在知道不会再有其他订阅者方法调用时调用,对于因错误而终止的订阅,在此之后不会再有其他订阅者方法
被调用。如果此方法抛出异常,则结果行为未定义。
public void onComplete();
}
Flow.Subscription是一种消息控制方式,连接了Flow.Publisher和Flow.Subscriber。订阅者只在请求时接收项目,并且可能在任何时候取消。该接口中的方法只应由其订阅者调用;在其他上下文中使用没有定义的效果。
public static interface Subscription {
将给定的n个项目添加到此订阅的当前未履行需求。如果n小于或等于零,则订阅者将收到带有
IllegalArgumentException参数的onError信号。否则,订阅者将收到多达n个额外的onNext调用(或更少,如果
终止)。
参数:n - 需求的增量; Long.MAX_VALUE的值可以被视为实际上无限制。
public void request(long n);
导致订阅者(最终)停止接收消息。实现是尽力而为的 - 在调用此方法后可能会收到额外的消息。取消的订阅不需要
收到onComplete或onError信号。
public void cancel();
}
一个组件,充当订阅者和发布者。类型参数:<T> - 订阅项类型;<R> - 发布项类型。
public static interface Processor<T,R> extends Subscriber<T>, Publisher<R> {
}
static final int DEFAULT_BUFFER_SIZE = 256;
返回发布者或订阅者缓冲的默认值,在没有其他限制的情况下可以使用。
返回值:缓冲大小值
实现说明:当前返回的值为256。
public static int defaultBufferSize() {
return DEFAULT_BUFFER_SIZE;
}
CompletableFuture
概述
CompletableFuture 是一个Future, 可以显式地完成(设置其值和状态), 并且可以用作CompletionStage, 支持依赖函数和在完成时触发的动作。 当两个或更多的线程尝试完成, completeExceptionally或取消CompletableFuture时, 只有其中一个成功。 除了这些和相关的直接操纵状态和结果的方法外, CompletableFuture还实现了以下策略的接口CompletionStage:
- 对于非异步方法的依赖完成提供的操作可能由完成当前 CompletableFuture 的线程或完成方法的任何其他调用者执行。
- 所有没有显式 Executor 参数的 async 方法都使用 ForkJoinPool.commonPool() 执行(除非它不支持至少两个并行级别,在这种情况下,将创建一个新线程来运行每个任务)。这可以在子类中通过定义 defaultExecutor() 方法来覆盖非静态方法。为简化监视,调试和跟踪,所有生成的异步任务都是 CompletableFuture.AsynchronousCompletionTask 标记接口的实例。具有延迟的操作可以使用此类中定义的适配器方法,例如:supplyAsync(supplier, delayedExecutor(timeout, timeUnit))。为了支持具有延迟和超时的方法,此类最多维护一个守护线程来触发和取消操作,而不是运行它们。
- 所有CompletionStage方法都是独立于其他公共方法实现的,因此一个方法的行为不会受到子类中其他方法重写的影响。
- 所有CompletionStage方法都返回CompletableFuture。要限制仅使用接口CompletionStage中定义的方法,请使用minimalCompletionStage方法。或者确保客户端不会自己修改未来,请使用copy方法。
CompletableFuture 同时实现了 Future 接口,并遵循以下策略。
- 因为(与FutureTask不同)这个类没有直接控制导致它完成的计算, 所以取消会被视为另一种特殊完成方式。cancel方法与completeExceptionally(new CancellationException())效果相同。isCompletedExceptionally方法可用于确定CompletableFuture是否以任何特殊方式完成。
- 这个类在异常完成时使用CompletionException,get()和get(long, TimeUnit)方法会抛出一个ExecutionException,其原因与CompletionException中所持有的相同。为了简化大多数上下文中的使用,这个类还定义了join()和getNow方法,在这些情况下直接抛出CompletionException。
在使用方法接受它们时用来传递完成结果的参数(即类型为T的参数)可能为空,但是为任何其他参数传递空值将导致抛出NullPointerException。 这个类的子类通常应该重写“虚拟构造函数”方法newIncompleteFuture,它确定了CompletionStage方法返回的具体类型。例如,这里有一个类替换了不同的默认执行程序并禁用了obtrude方法:
class MyCompletableFuture<T> extends CompletableFuture<T> {
static final Executor myExecutor = ...;
public MyCompletableFuture() { }
public <U> CompletableFuture<U> newIncompleteFuture() {
return new MyCompletableFuture<U>(); }
public Executor defaultExecutor() {
return myExecutor; }
public void obtrudeValue(T value) {
throw new UnsupportedOperationException(); }
public void obtrudeException(Throwable ex) {
throw new UnsupportedOperationException(); }
}
CompletableFuture是一种可以有依赖完成动作的未来对象,这些动作被收集在一个链接堆栈中。它通过CAS操作完成结果字段,然后弹出并运行那些动作。这适用于正常情况与异常情况,同步与异步动作,二进制触发器和各种形式的完成。
volatile字段“result”的非空性表示完成。如果已知是线程限制的,则可以直接设置,否则通过CAS设置。AltResult用于将空值作为结果盒装,以及用于保存异常。使用单一字段使完成简单易检测和触发。结果编码和解码是直接的但繁琐的,并增加了捕获和将异常与目标关联的范围。小简化依赖于(静态)NIL(将空结果盒装)是唯一具有空异常字段的AltResult,因此我们通常不需要明确比较。尽管一些泛型转换是不检查的(请参见SuppressWarnings注释),但即使检查也是适当的。
其中依赖动作由Completion对象表示,这些对象通过“stack”字段链接在一起,构成一个Treiber堆栈。有各种动作的Completion类,分为:
- 单输入(UniCompletion)
- 双输入(BiCompletion)
- 投影(BiCompletions使用两个输入中的一个)
- 共享(CoCompletion,由第二个输入源使用)
- 零输入源动作
- Signallers,用于解除阻塞等待。
Completion类扩展了ForkJoinTask,可异步执行(因为我们利用其“tag”方法维护声明,所以不会增加额外空间开销)。它还声明为Runnable,以允许使用任意执行器。
每种CompletionStage都有一个单独的类来支持,并且还有两个CompletableFuture方法:
-
一个名为X的Completion类对应着一个带有"Uni","Bi"或"Or"前缀的函数。每个类都包含来源,操作和依赖项的字段。它们非常相似,只有在底层函数形式上有所不同。我们这样做是为了让用户在常见用法中不会遇到适配器层。
-
Boolean CompletableFuture方法x(...) (例如biApply)接受所有需要检查操作是否可触发的参数,然后运行操作或通过执行其Completion参数安排其异步执行(如果存在)。如果已知完成,则该方法返回true。
-
Completion方法tryFire(int mode)使用其保存的参数调用关联的x方法,并在成功时清理。mode参数允许tryFire被调用两次(SYNC,然后ASYNC);第一次是在安排执行时进行屏幕和陷阱异常,第二次是在从任务调用时。(有些类没有异步使用,所以形式略有不同)。claim()回调在另一个线程已经声明时会屏蔽函数调用。
-
一些类(例如UniApply)有单独的处理代码,用于已知的线程限制("now"方法)和共享(在tryFire)中,以提高效率。
-
CompletableFuture方法xStage(...)从CompletableFuture f的公共阶段方法调用。它对用户参数进行筛选并调用和/或创建阶段对象。如果不是异步的并且已经可触发,则立即运行操作。否则,将创建一个Completion c,并在可触发时提交到执行器,或者在不可触发时压入f的堆栈。完成操作通过c.tryFire启动。在推送到源未来的堆栈后我们重新检查,以覆盖在推送时源完成的可能竞争。具有两个输入的类(例如BiApply)在推送操作时处理两者之间的竞争。第二个完成是指向第一个的CoCompletion,共享,以便最多只有一个执行操作。多值方法allOf通过成对形成完成的树。方法anyOf与allOf不同,因为任何源的完成都应该触发其他源的cleanStack。每个AnyOf完成都可以通过共享数组访问其他。
请注意,方法的泛型类型参数根据"this"是源、依赖项还是完成情况而变化。
postComplete 方法在目标完成后调用,除非目标不能被观察到(即尚未返回或链接)。多个线程可以调用 postComplete,它原子地弹出每个依赖操作,并尝试通过 tryFire 方法触发它,在 NESTED 模式下。触发可能会传播递归,因此 NESTED 模式返回其已完成的依赖项(如果存在),供其调用者进一步处理(参见 postFire 方法)。
阻塞方法 get() 和 join() 依赖于 Signaller Completions,它们唤醒等待中的线程。这种机制类似于 FutureTask、Phaser 和 SynchronousQueue 中使用的 Treiber stack wait-nodes。有关算法细节,请参见它们的内部文档。
如果没有预防措施,CompletableFutures 将容易产生垃圾累积,因为每个指向其源的 Completions 链都会建立起来。因此,我们尽早地将字段设置为 null。需要进行筛选检查的检查无害地忽略了可能在与线程竞争时获得的 null 参数。我们还试图从可能永远不会被弹出的堆栈中解除非 isLive(已触发或已取消)的 Completions:cleanStack 方法总是从堆栈的头部解除非 isLive 完成;如果与其他取消或删除竞争,其他完成可能偶尔仍然存在。
由于完成字段只在安全发布后对其他线程可见,因此无需将它们声明为 final 或 volatile。