Redis事件驱动
概述
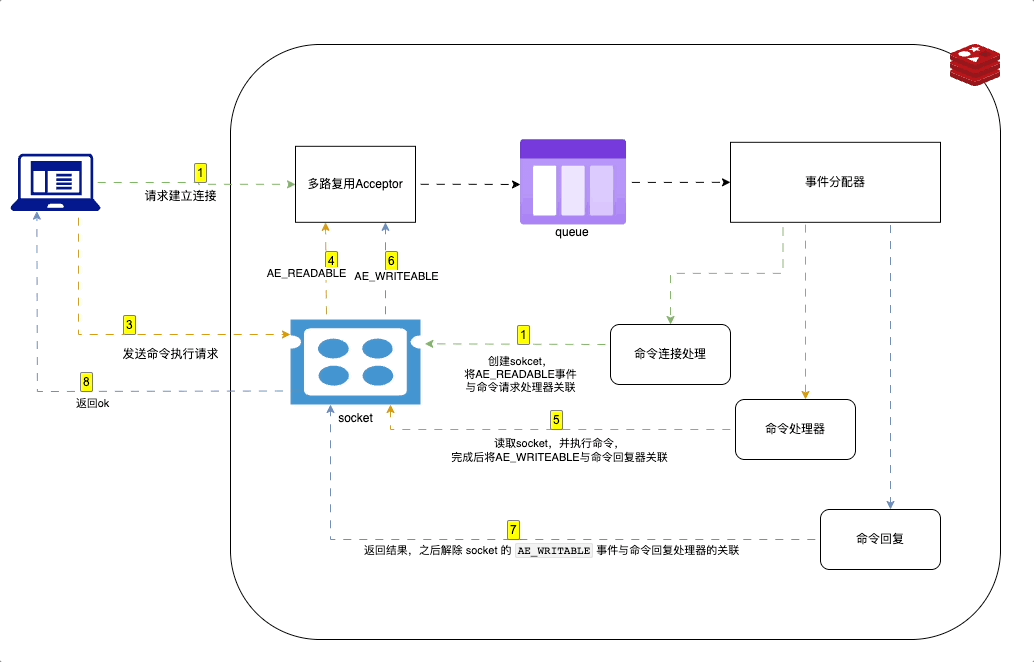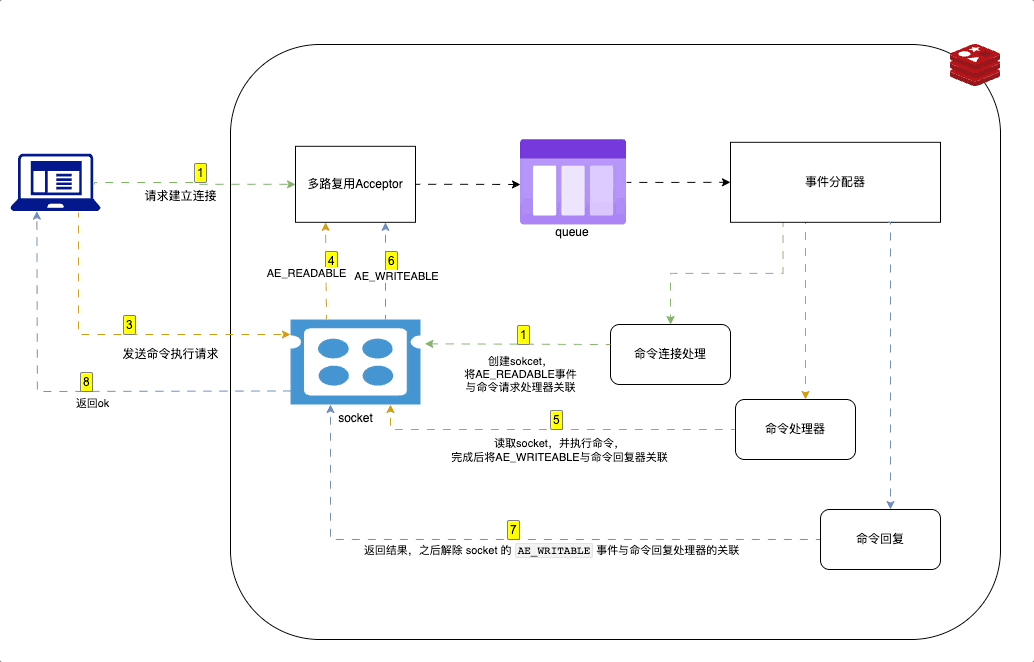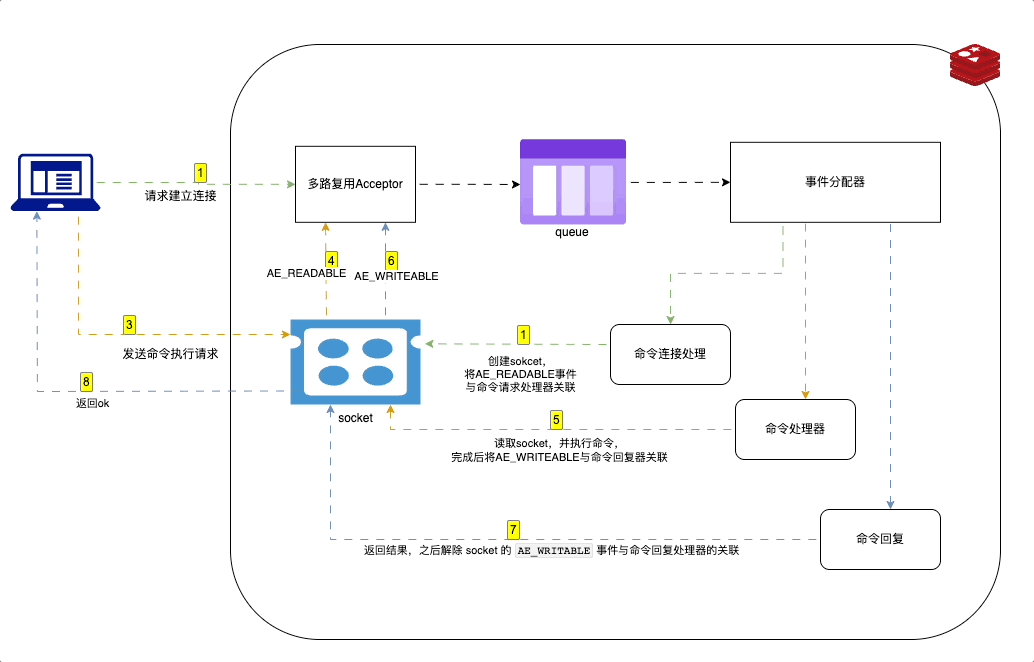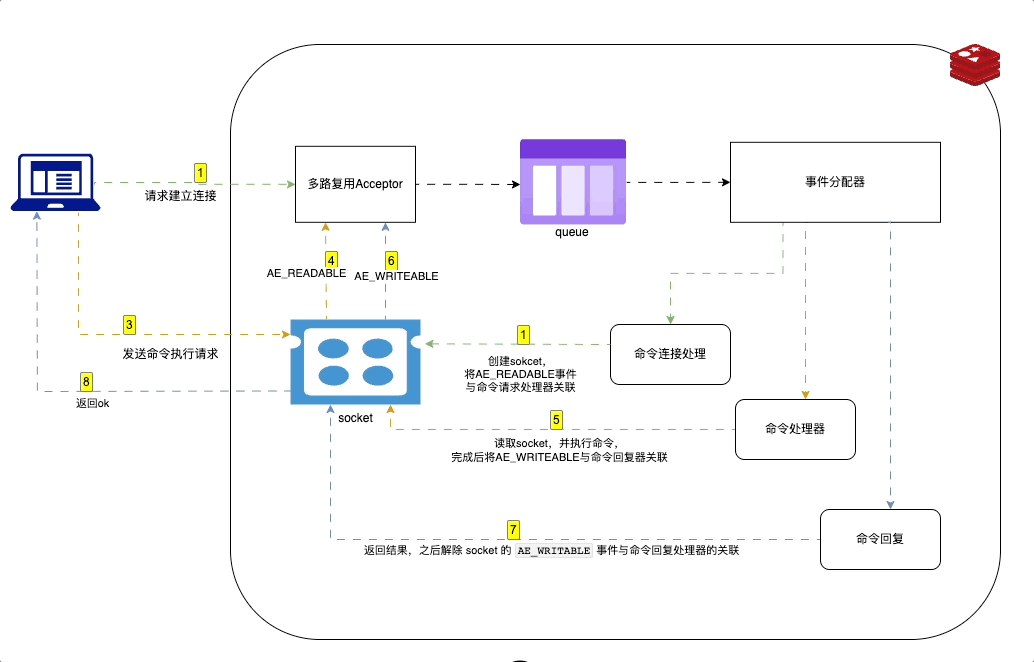
Redis 中使用事件驱动模型来处理客户端请求和服务器响应。采用 I/O 多路复用技术。
在 Redis 中,事件驱动的工作原理如下:
- Redis 服务器初始化一个事件循环,并在其中监听套接字描述符的 I/O 事件。
- 当有新的客户端连接请求时,server socket 会产生一个
AE_READABLE事件,并将其放入到队列中。 - 命令连接处理器创建socket连接,并将AE_READABLE事件与命令请求处理器关联。
- 客户段发送命令请求,产生可读事件,事件循环监听到之后压入队列,事件分配器发送给命令请求处理器。读取socket内容,执行命令,完成后将AE_WRITEABLE事件与命令回复器关联
- 如果客户端以准备好接收结果,socket会产生AE_WRITEABLE事件,然后继续压入队列,被命令回复处理器 处理 并返回结果。
Redis Pub/Sub
SUBSCRIBE,UNSUBSCRIBE 和 PUBLISH 实现了发布/订阅消息范式,其中发送者(发布者)不会直接发送消息给特定的接收者(订阅者)。相反,发布的消息被归类到通道(Channel)中,发布者并不知道是否有订阅者。订阅者对一个或多个通道表达兴趣,并且只接收感兴趣的消息,不知道是否有发布者。
1.基本的发布订阅

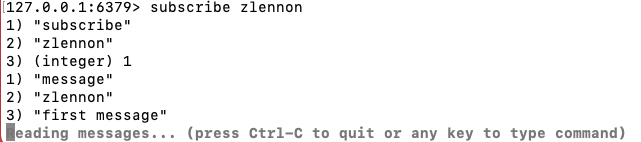
2.模式匹配


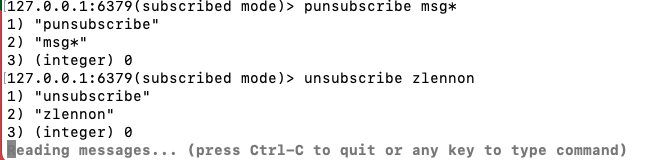
3. 取消订阅
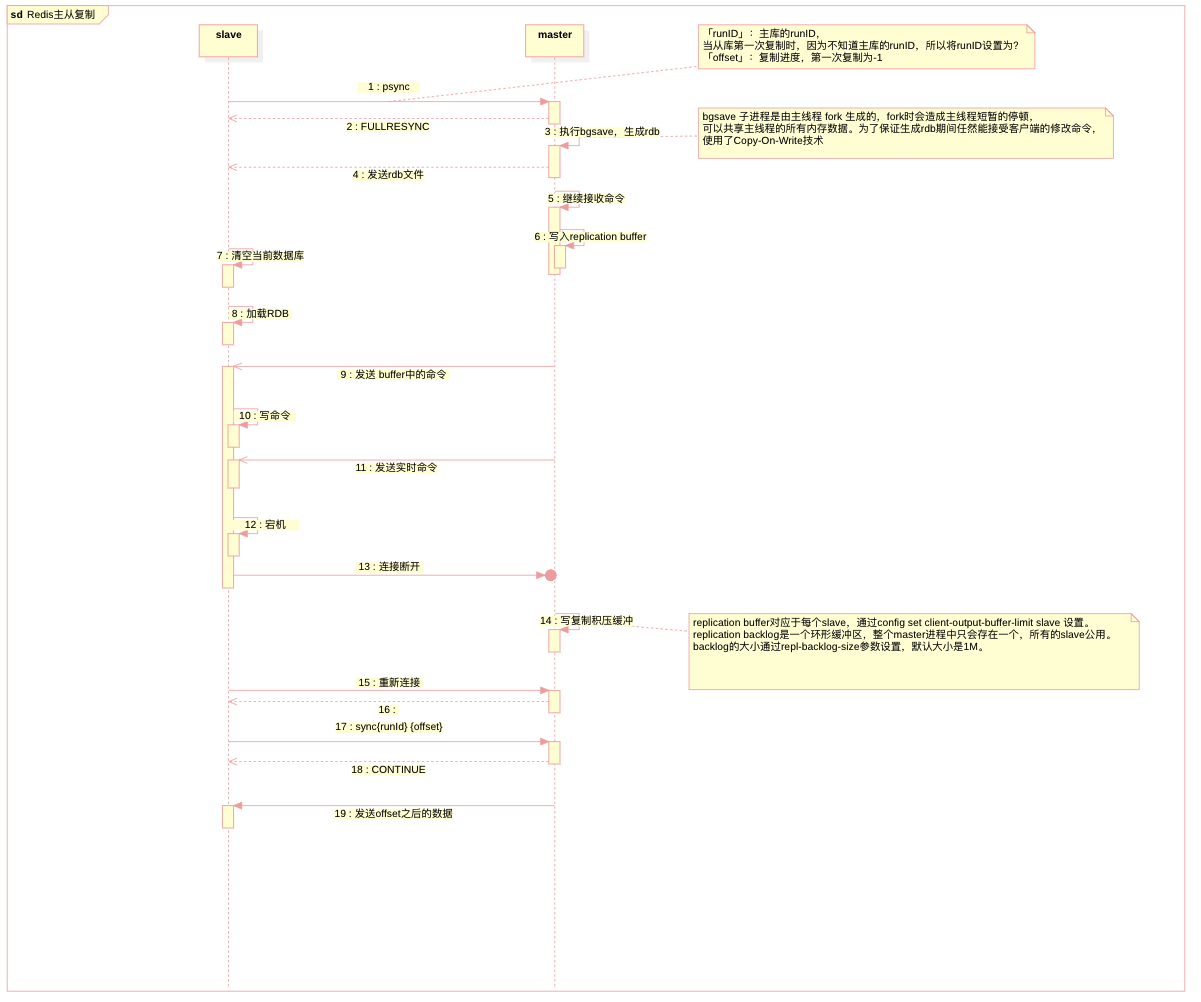
主从复制
Redis主进程fork生成的子进程可以共享主进程的所有内存数据,fork并不会带来明显的性能开销,因为不会立刻对内存进行拷贝,它会将拷贝内存的动作推迟到真正需要的时候。 如果主进程是读取内存数据,那么和BGSAVE子进程并不冲突。如果主进程要修改Redis内存中某个数据,那么操作系统内核会将被修改的内存数据复制一份(复制的是修改之前的数据),未被修改的内存数据依然被父子两个进程共享,被主进程修改的内存空间归属于主进程,被复制出来的原始数据归属于子进程。如此一来,主进程就可以在快照发生的过程中肆无忌惮地接受数据写入的请求,bgsave完成之后将新写的数据也写进rdb文件
redis server会为每一个连接到自己的客户端创建一个replication buffer,用来缓存主库执行的命令。等从库加载完成RDB文件后,主库就会把缓存的命令发送给从库
i/o多路复用程序的实现
redis的i/o复用程序底层实现了select,epoll,evport和kqueue这些i/o多路复用函数库,他们实现了相同的api,所以底层实现可以互换(工厂模式)。
select
在调用select函数时,应用程序会将需要监视的文件描述符集合传递给内核。内核会遍历这些文件描述符,检查它们的状态是否发生变化(如是否可以读取、是否可以写入等)。如果有文件描述符的状态发生变化,内核会将这些文件描述符添加到就绪列表中,然后返回给应用程序。
epoll
epoll使用了事件就绪通知机制。应用程序通过调用epoll_ctl函数向内核注册需要监视的文件描述符,并指定感兴趣的事件类型(如可读、可写等)。当有文件描述符的状态发生变化时,内核会立即将这些事件通知给应用程序,而不需要应用程序轮询文件描述符的状态。
evport
kqueue
Redis数据类型
主要提供了5种数据类型:字符串(string)、哈希(hash)、列表(list)、集合(set)、有序集合(zset)。Redis还提供了Bitmap、HyperLogLog、Geo类型,但这些类型都是基于上述核心数据类型实现的。5.0版本中,Redis新增加了Streams数据类型,它是一个功能强大的、支持多播的、可持久化的消息队列。
1. string可以存储字符串、数字和二进制数据,除了值可以是String以外,所有的键也可以是string,string最大可以存储大小为512M的数据。
2. list保证数据线性有序且元素可重复,它支持lpush、blpush、rpop、brpop等操作,可以当作简单的消息队列使用,一个list最多可以存储2^32-1个元素。
3. hash的值本身也是一个键值对结构,最多能存储2^32-1个元素。
4. set是无序不可重复的,它支持多个set求交集、并集、差集,适合实现共同关注之类的需求,一个set最多可以存储2^32-1个元素。
5. zset是有序不可重复的,它通过给每个元素设置一个分数来作为排序的依据,一个zset最多可以存储2^32-1个元素。
每种类型支持多个编码,每一种编码采取一个特殊的结构来实现,各类数据结构内部的编码及结构:
- string:编码分为int、raw、embstr。int底层实现为long,当数据为整数型并且可以用long类型表示时可以用long存储。embstr底层实现为占一块内存的SDS结构,当数据为长度不超过32字节的字符串时,选择以此结构连续存储元数据和值。raw底层实现为占两块内存的SDS,用于存储长度超过32字节的字符串数据,此时会在两块内存中分别存储元数据和值。
- list:编码分为ziplist、linkedlist、quicklist(3.2以前版本没有quicklist)。ziplist底层实现为压缩列表,当元素数量小于512且所有元素长度都小于64字节时,使用这种结构来存储。linkedlist底层实现为双端链表,当数据不符合ziplist条件时,使用这种结构存储。3.2版本之后list采用quicklist的快速列表结构来代替前两种。
- hash:编码分为ziplist、hashtable两种。其中ziplist底层实现为压缩列表,当键值对数量小于512,并且所有的键值长度都小于64字节时使用这种结构进行存储。hashtable底层实现为字典,当不符合压缩列表存储条件时,使用字典进行存储。
- set:编码分为inset、hashtable。intset底层实现为整数集合,当所有元素都是整数值且数量不超过512个时使用该结构存储,否则使用字典结构存储。
- zset:编码分为ziplist、skiplist。当元素数量小于128,并且每个元素长度都小于64字节时,使用ziplist压缩列表结构存储,否则使用skiplist的字典+跳表的结构存储。
Redis没有直接使用C语言传统的字符串表示,而是自己构建了一种名为简单动态字符串(Simple Dynamic String),即SDS的抽象类型,并将SDS用作Redis的默认字符串表示。每个sds.h/sdshdr结构表示一个SDS值,它有三个属性,这里我们举个例子:

<di>
· len属性值为5,代表这个SDS存了一个五字节长的字符串;
· buf属性是一个char类型的数组,数组的前五个字节分别保存了‘H’、‘e’、‘l’、‘l’、‘o’ 五个字符,而最后一个字节则保存了空字符‘’。
SDS遵循C字符串以空字符结尾的惯例,保存空字符的一字节空间不计算在SDS的len属性中。为空字符串分配1字节的额外空间以及添加空字符到字符串末尾等操作都是由SDS函数自动完成的,所以这个空字符串对于SDS的使用者来说完全透明。遵循空字符串的好处是,SDS可以直接重用一部分C字符串函数库里的函数。
</di>
分享到:
{kind=link}